
Probability theory#
To begin developing a theory of probability, it is useful to consider a simple random process such as a flipping a coin. There are two possible outcomes of a single coin toss, “Heads” or “Tails,” which we’ll denote \(H\) and \(T\), respectively.
The sample space is the set of possible outcomes:
indicating that one of these two events must occur.
A coin flip is an example of a random process that has two possible outcomes, called a Bernoulli trial, where the probability of the event occuring is given by \(p\) (and, obviously, of it not occuring by \(1-p\)). If a coin is fair, the probability of Heads (or, equivalently, of Tails) is \(p=0.5\).
Examples of binary outcomes that can be modeled as Bernoulli trials include:
a single coin flip comes up Heads;
a customer chooses whether to buy a product;
a company declares bankruptcy next week; or
a stock price increases in the next 15 seconds.
Each outcome \(\omega \in \Omega\) has an associated probability, given by the probability measure \(\P: \Omega \rightarrow [0,1]\). For a fair coin flip,
To be sensible, the probability measure must be defined such that the probability that some event in the sample space occuring is 1, so
In other words, the probability that something happens is one. As a matter of logic, if that weren’t true, we would have to redefine the sample space. If it is correctly defined as the exhuastive set of all possible outcomes, then one of those outcomes must occur.
Random variables#
A random variable is a function that maps an event to a real number. For example, define the random variable \(X\) to be the number of Heads that we observe in a single coin flip,
This says simply that if the event \(\omega=T\) occurs then \(X=0\), and if the event \(\omega=H\) occurs then \(X=1\). In general, a random variable (“RV”) maps from an event space to some real number: \(X\!: \Omega \rightarrow \mathbb{R}\).
We can then apply the probability measure to \(X\). For some \(x\in \mathbb R\),
In words, this says simply that the probability that the random variable \(X\) takes on a value of \(x\) is equal to the probability that an outcome \(\omega\) occurs that causes \(X\) to equal \(x\). Therefore,
It is common practice to write simply \(\P(x)\) rather than \(\P(X=x)\).
More generally, a random variable defined for a Bernoulli trial with probability \(p\) is
The event that leads to \(X=1\) is often called “success.”
Let’s apply the same framework to an experiment where we flip a coin twice. As before, the sample space is the set of possible outcomes:
The probability measure is
As expected, \(\P(\Omega) = 1.\) Again, define the random variable \(X\) to be the number of Heads that we observe in our two coin flips,
Applying the probability measure to \(X\),
Formally, an event is any subset of \(\Omega\). For example, the event that at least one of the flips is Heads is
The probability of this event is the sum of the probabilities of each element in the event,
Exercise
Suppose you roll a single six-sided die. Define the random variable \(X\) to be the number shown on the die. What is the sample space? What are the probabilities associated with each possible value of the \(X\)?
Extra credit
Modern probability theory, introduced in the 1930s by Andrey Kolmogorov, is formally defined using a probability space \((\Omega, \mathcal{F}, \P)\), where \(\mathcal{F}\) is the set of all possible events is (called the event space or the “\(\sigma\)-algebra”). In the two-flip example, this is
In this example, \(\Omega\) is countable, so \(\mathcal{F}\) is the power set of \(\Omega\), and its cardinality (the number of elements in the set) is \(2^4=16\). More generally, though, the sample space need not be countable, and a different \(\sigma\)-algebra must be used. A nice introduction to these ideas may be found on Wikipedia.
Binomial distribution#
Generalizing from two coin flips, suppose that we repeat a Bernoulli trial \(n\) times. The trials are assumed to be mutually independent, meaning that the outcome of each trial has no effect on any other outcomes. Let \(X\) equal the number of Heads out of these trials. We characterize the random variable \(X\) by determining \(\P(X=k)\) for any possible value of \(k\). This is given by the probability mass function (PMF),
A random variable with this PMF has a Binomial distribution, which we write as \(X \sim B(n,p)\).
Exercise
Show that when \(n=1\) this PMF reduces to probability function for a Bernoulli trial.
Solution
We have
and
which matches the function in (9).
The PMF for the Binomial distribution (along with many others) is available in the scipy module. Here we calculate \(f(k; 3, 0.5)\) for each possible \(k\).
n = 3 # number of trials
p = 0.5 # probability of success in each trial
scs.binom.pmf([0, 1, 2, 3], n, p)
array([0.125, 0.375, 0.375, 0.125])
As we increase \(n\), the probabilities associated with each outcome change, and so does the shape of the PMF.
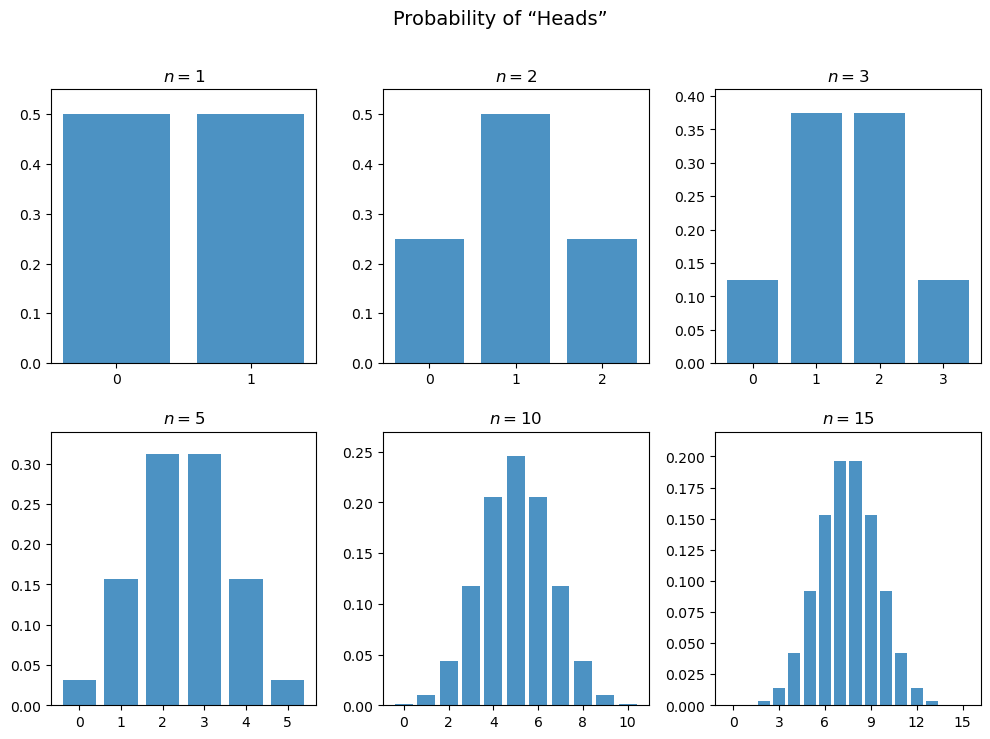
Expected value and variance#
The expected value or expectation of a discrete random variable \(X\) with possible outcomes \((x_1, x_2, \ldots, x_n)\) is the weighted average of the outcomes,
The expected value, often denoted by the Greek letter \(\mu\), measures the location or central tendency of the distribution.
For example, suppose we flip a fair coin 3 times, and assign to \(X\) the number of times Heads comes up, so \(X\sim B(3,0.5)\). The sample space is
so the random variable \(X\) has these possible values:
The expectation of \(X\) is therefore
As this example makes clear, the expected value of \(X\) need not be a value from any outcome in its sample space.
Key fact
The expecation of a random variable is the average of the population. For a random process like rolling a die, this is the average we would get if we could repeat the process infinitely many times.
The variance of \(X\) is a measure of how much the probability mass is spread out around its expected value. It is defined as the weighted sum of the squared deviations from the expected value,
The variance is typically denoted by \(\sigma_X^2\). Its square-root, \(\sigma_X\), is the standard deviation of the distribution.
Continuing to define \(X\) as above, we have
The scipy module provides the expected value (also called the mean), variance, and standard deviation of a random variable given the parameters of its distribution.
B = scs.binom(3, 0.5)
print(B.mean())
print(B.var())
print(B.std())
1.5
0.75
0.8660254037844386
Exercise
Find the expected value and variance of a Bernoulli random variable.
Solution
Using the defition of expectation and variance,
The following code uses assert to verify that a boolean expression is True; if it isn’t, an exception is raised. These conditions are all true, so the code executes without raising any exceptions.
for p in [0.1, 0.4, 0.99]:
assert scs.bernoulli(p).mean() == p
assert scs.bernoulli(p).var() == p*(1-p)
Linearity of expectations#
We saw above that the mean and variance of a distribution are defined using the expectations operator \(\E\) which we redefine here as applying to any function \(g(\cdot)\) of the random variable \(X\),
In the simplest case that we previously considered, \(g(x)=x\). It follows immediately that, for any constant \(a\),
This holds for any nonrandom — also called nonstochastic — variable. In other words, if \(a\) doesn’t depend on the outcome \(\omega\) then its value isn’t random, and its expectation is just \(a\).
Exercise
Find the variance of a constant \(a\).
Solution
Applying the definition of variance,
Not surprisingly, \(a\) has no variance — it’s constant!
More generally, we can show that the expectations operator \(\E\) is linear. Let \(Z=a+bX\) for some constants \(a\) and \(b\). Then
Exercise
Use the definition of the \(\E\) operator to show that if \(X\) and \(Y\) are two random variables then
for two arbitrary constants \(a\), \(b\), and \(c\). (Note that when we say \(X\) and \(Y\) are two random variables, we mean that they are both functions of elements of the same outcome space \(\Omega\).)
The variance, however, is not linear:
In particular, this implies that
which is especially important when we calculate the volatility of portfolios that include short positions.
Key fact
We can use these facts to shift and rescale a random variable.
For example, suppose we have a random variable \(X\) with \(\E(X)=0\) and \(\var(X)=1\). If we create a new random variable
then \(\E(Y) = \mu\) and \(\var(Y) = \sigma^2\). We have shifted the mean by \(\mu\) and rescaled it to have a variance of \(\sigma^2\).
Key fact
The linearity of the expectations operator allows us to write variance conveniently as
Exercise
The random variable \(Y\) follows a Binomial distribution with parameters \(n\) and \(p\). Find \(\E(Y)\) and \(\var(Y)\).
Solution
Since \(Y\sim B(n,p)\), it is the sum of \(n\) independent Bernoulli trials. We saw previously that if \(X\) has a Bernoulli distribution then \(\E(X)=p\) and \(\var(X)=p(1-p)\). Therefore,
and
The first result is quite intuitive: If we flip a fair coin \(n\) times, we would expect it to come up Heads \(0.5\times n\) times. But of course it might turn up Heads more or less than that. The variance, in this case \(0.25\times n\), tells us how variability we can expect in the outcome. We will soon delve into this more deeply.
Note also that the calculation of the variance here is correct only because we assumed that the the Bernoulli trials are independent; that is, the outcome of each trial has no effect on the outcomes of other trials. If the trials are related in some way, these calculations no longer hold, as we’ll see when we discuss covariance.
The normal distribution#
Consider what happens as we increase the number of trials. The figure shows the distribution of outcomes according to the binomial distribution along with a continuous function called the normal distribution. (Move the slider to increase \(N\).)
Number of trials: 1
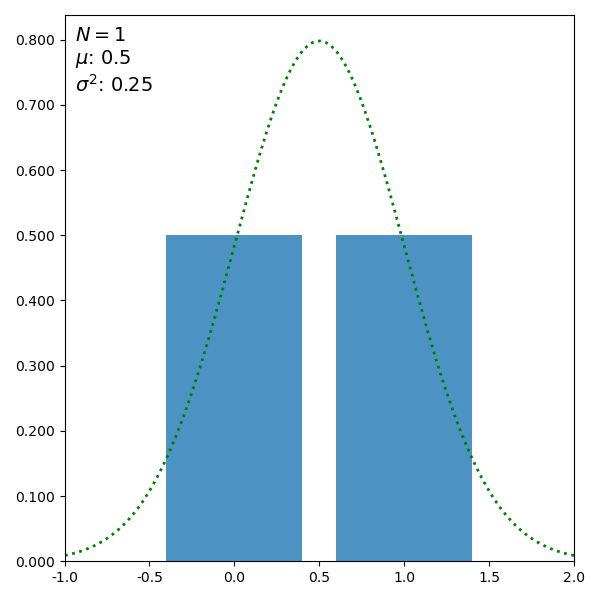
In particular, suppose \(n=50\), so \(\E(X)=25\) and \(\var(X)=12.5\).
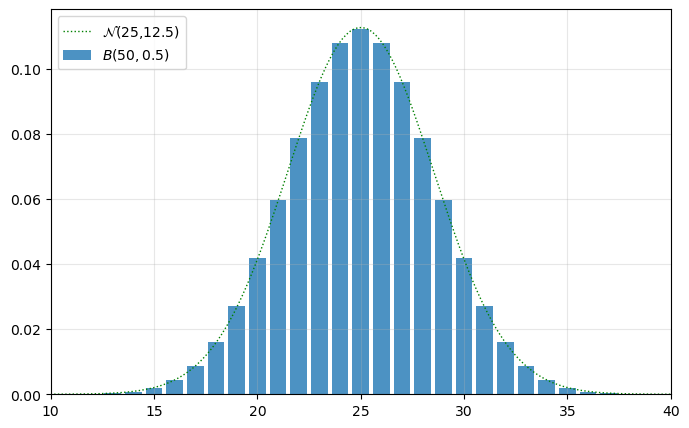
The fit of this curve to the binomial distribution is very good — the line and bars match exactly for most values of \(X\). As \(n\) increases, the fit continues to get better; in the limit, the binomial distribution converges to the normal distribution.
In contrast to the binomial distribution, which is only defined over discrete values \(k=\{0, 1, \ldots, n\}\), the normal distribution is a continuous distribution, defined over the entire real line. Like all such continuous distributions, it is characterized by a probability density function (PDF) that is defined over a continuous domain. (In the graphs above, we’re only plotting the distribution over the same domain as the binomial distribution, but the normal PDF is actually defined everywhere.)
The PDF for a random variable \(X\) with a normal distribution, which we write as \(X \sim \N(\mu,\sigma^2)\), is given by
Note
It is easy to get confused by the difference between \(\E(X)\) and \(\mu\). As we have seen, \(\E(X)\) is the expected value of the random variable \(X\), regardless of what kind of random variable it is. It is a number we calculate by applying the expectations operator \(\E\) to the random variable.
If we calculate an expected value of a random variable with the Normal distribution, \(X\sim\N(\mu, \sigma^2)\), using the method explained below, we will find that
That is, when a random variable has the pdf \(f_X(x; \mu, \sigma)\) shown above, it just so happens that the expected value of this random variable is equal to the parameter value \(\mu\).
Since the normal distribution is so important and pervasive, its expected value \(\mu\) is often used as a general symbol for the more general concept of \(\E(X)\). But, as we will soon see, there are many random variables where the expected value is not a simple parameter of their distribution. It just happens to be true with normally-distributed random variables.
The parameters \(\mu\) and \(\sigma\) control the location and shape of the distribution. With \(\mu=0\) and \(\sigma=1\), we have the “standard” normal distribution, \(X \sim \N(0,1)\), with density
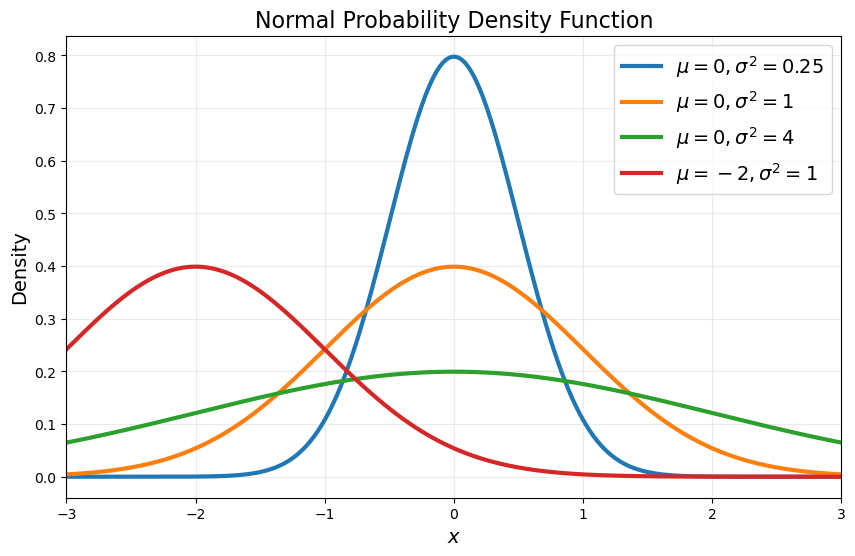
You can try different combinations of parameters to see how the shape and center of the distribution shift:
μ=0.00 σ=1.00
Rather than directly giving probabilities, the PDF is a tool for calculating the probability. In particular, we integrate under the curve to find the cumulative distribution function (CDF), which gives the probability that the random variable \(X\) is less than a given value \(x\):
The CDF and PDF of a normal distribution are often written as \(\Phi(x)\) and \(\phi(x)\), respectively.
Select a value for \(x\): 0.0
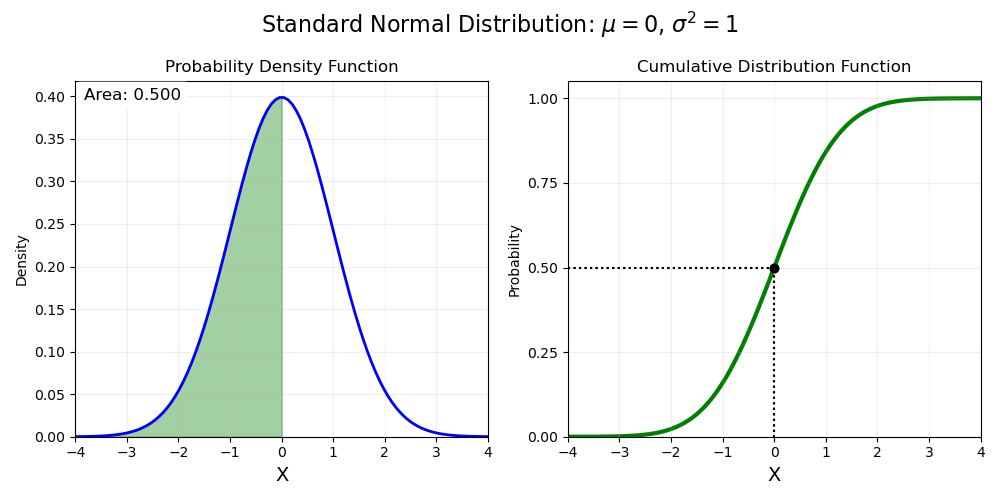
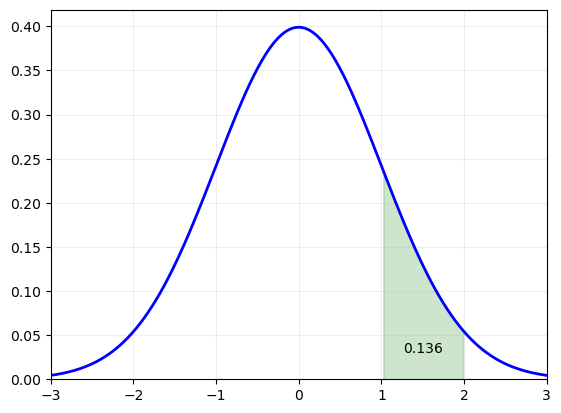
We can calculate the probability that \(X\) is between \(a\) and \(b\) (with \(a<b\)) by calculating
For example, the probability that a random draw of \(X\sim \N(0,1)\) will be between 1 and 2 is:
area = scs.norm().cdf(2) - scs.norm().cdf(1)
print(area)
0.13590512198327787
A valid CDF must have the following properties:
\(F(x)\) is non-decreasing, meaning that \(f(x)\geq 0\) for all \(x\);
\(0\leq F(x)\leq 1\); and
\(F(-\infty)=0\) and \(F(\infty)=1\).
Intuitively, \(F(\infty)=1\) because the probability that \(X\) will be less than infinity must be one: \(X\) has to have a realization somewhere on the real line. For the same reason, \(F(-\infty)=0\).
The fact that \(F(\infty)=1\) explains why we divide by \(\sqrt{2\pi}\) in the normal density function; it is simply a normalizing constant to force the probability to be one in the limit. To see why this is the necessary constant, refer to our previous discussion of the Gaussian integral.
Warning: A PDF is not a ``probability function’’
There are two important facts about probability density functions that may seem surprising at first:
\(f(x)\) does not give the probability of \(x\). It is simply an input to the calculation of the probability of a possible outcome.
Since \(f(x)\) is not a probability, there is no reason that it must be less than 1. It must, however, never be negative. (Using the sliders above, you can find values of \(\sigma\) that will make the density function have values greater than one.)
Perhaps most surprising is the fact that \(\P(X=x)=0\) for any \(x\). Yes, you read that right: the probability that \(X\) takes on any particular value is zero. We can see this by using the definition of the CDF:
Ituitively this is because there are an infinite number of outcomes so the probability of any one of them is \(\frac{1}{\infty} = 0\).
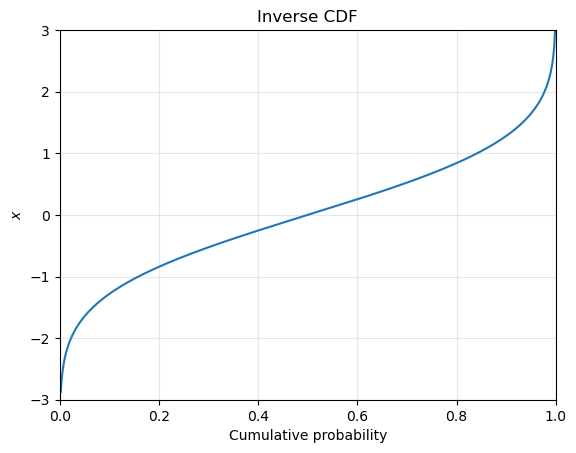
Inverse CDF#
The inverse of the CDF function allows us to answer the question “what value of a random draw from \(X\) would have a probability of less than \(p\) of happening?”. Rather than giving the probability associated with a realization of the random variable, it gives us what realization would be a associated with a given level of probability. In SciPy, the ppf function (“percent point function”) gives these values.
p = np.array([0.005, 0.01, 0.025, 0.05, 0.5, 0.95, 0.975, 0.99, 0.995])
pd.DataFrame({
'probability': p,
'value': scs.norm().ppf(p)}
).set_index('probability')
| value | |
|---|---|
| probability | |
| 0.005 | -2.575829 |
| 0.010 | -2.326348 |
| 0.025 | -1.959964 |
| 0.050 | -1.644854 |
| 0.500 | 0.000000 |
| 0.950 | 1.644854 |
| 0.975 | 1.959964 |
| 0.990 | 2.326348 |
| 0.995 | 2.575829 |
That is, there is a 2.5% chance that a draw from a standard normal distribution would have a value of less than –1.96. Because the distribution is symmetric, there is also a 2.5% chance that the draw would be greater than 1.96 (that is, there’s a 97.5% that it would be less than 1.96). We will revisit these well-known “critical values” when we discuss parameter estimation.
Expected value of continuous RVs#
The expected value of a continuous random variable is defined analagously to the defintion above for the discrete case:
Again, it is simply the weighted average of all possible values of \(x\). The only difference is that we calcualate the probability over the entire real line, and we use the PDF instead of the PMF.
Similarly, the variance of a continuous random variable is
As noted above, it can be shown for the normal distribution that the two parameters of the density function, \(\mu\) and \(\sigma^2\), are equal to the expected value and variance of the distribution, \(\E(X)\) and \(\var(X)\), respectively.
Exercise
The code below uses quadrature to calculate the integral for the expected value of \(X\sim\N(\mu,\sigma)\). If you change the parameter μ and run the code, you will find that the integral is always equal to whatever value of μ you chose. This should convince you that the expected value is, in fact, \(\mu\).
from scipy.integrate import quad
# Parameters for the normal distribution
μ = 3.5
σ = 1
# Define the PDF of the normal distribution
def normal_pdf(x, μ, σ):
return (1 / (σ * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - μ) / σ) ** 2)
# Define the function to integrate
def pdf_times_x(x, μ, σ):
return x * normal_pdf(x, μ, σ)
# Integrate the function from -∞ to ∞
result, error = quad(pdf_times_x, -np.inf, np.inf, args=(μ, σ))
print(f"Integral result: {result:0.4f}, with error estimate: {error:0.2e}")
Another way to do the same kind of exercise is to confirm that the theoretical expected value (``mean’’) and variance reported by scipy equals what we expect, which is what this code does:
for μ in [-1, 0, 1]:
for σ in [0.5, 2, 4]:
X = scs.norm(μ,σ)
assert (X.mean() == μ) and (X.var() == σ**2)
Make sure you understand the following:
What does
scs.norm(μ,σ)do?What calculation is happening when we call
X.mean()andX.var()? Specifically, can you point to an equation somewhere on this page that is being calculated?What does
assertdo in this code?
This fact—and that the normal distribution is so important throughout statistics—is of course the reason that we use the symbols \(\mu\) and \(\sigma^2\) both for the parameters of the probability distribution and as general symbols for mean and variance.
As \(\sigma\) increases, both the PDF and CDF becomes flatter to reflect the greater probability of a wider range of outcomes.
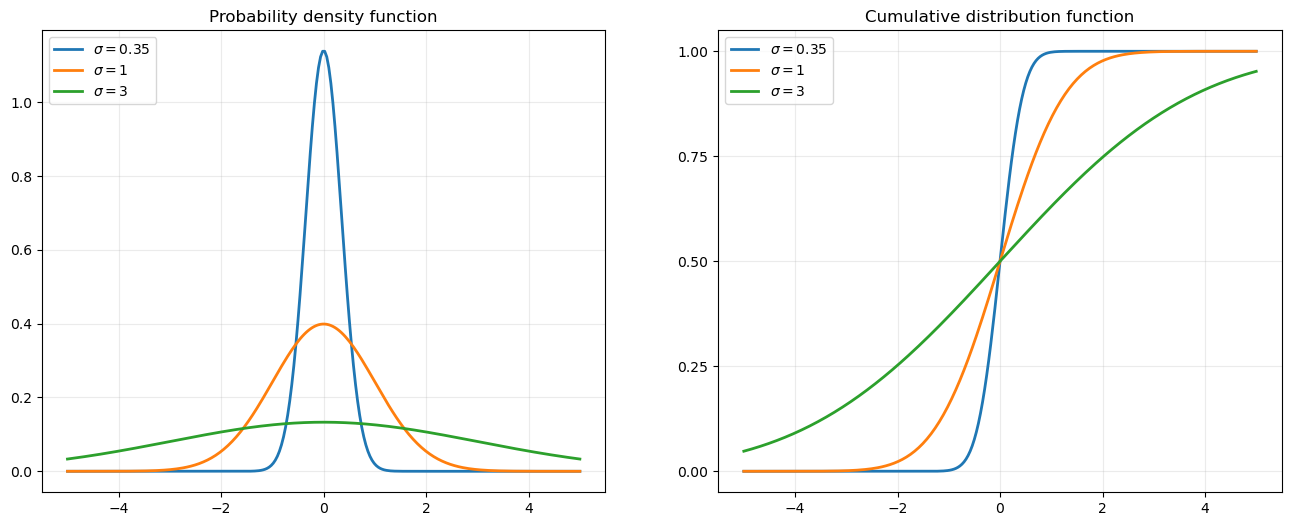
Exercise
Make a plot like the one above to show how the PDF and CDF shift to the left or right as we change \(\mu\).
Higher-order moments#
The expected value is also called the first moment of \(X\). More generally, the \(k\)th moment is \(\E(X^k)\).
Central moments are defined around the mean. For example, variance is the second central moment:
Higher-order moments can be similarly defined; the \(k\)th central moment is
Extra credit
Use properties of \(f_X(x)\) to show that \(\mu_0 = 1\) and \(\mu_1\) = 0.
The skewness and kurtosis are, respectivley, the third and fourth standardized moments — that is, the central moment divided by the standard deviation to make the ratio unitless:
These moments are all helpful in characterizing what a distribution “looks like.” The mean tells us where the center of the distribution is; the variance measures the dispersion around the mean; the skewness describes the asymmetry of the distribution; and kurtosis measures how “thick” its tails are.
The skewness of a normal distribution is 0. The kurtosis is 3, and because the normal distribution is so foundational, people usually refer to \(\operatorname{Kurt}[X]-3\) as simply the excess kurtosis.