
Implementing regressions#
We begin by generating some data to work with. We’ll use the same data we used in the previous section.
from numpy.random import default_rng
rng = default_rng(8675309)
N = 100
x = rng.uniform(high=10, size=(N,1))
ε = rng.normal(0, 7, size=(N,1))
y = 2 - 3*x + ε
statsmodels#
import statsmodels.api as sm
In statsmodels we can construct the design matrix simply by calling the .add_constant() method. This simply adds a column of ones to the beginning of the \(X\) matrix.
X = sm.add_constant(x)
X[:5]
array([[1. , 3.78932572],
[1. , 8.14510763],
[1. , 6.25815208],
[1. , 9.06732906],
[1. , 1.51201567]])
We then create our model and fit it. The most basic regression model is called the Ordinary Least Squares (OLS) model, which we use here. We store the results object from the fit() method in results.
model = sm.OLS(y, X)
results = model.fit()
We can see the regression output by calling the summary() method of this results object.
print(results.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.672
Model: OLS Adj. R-squared: 0.668
Method: Least Squares F-statistic: 200.6
Date: Tue, 17 Feb 2026 Prob (F-statistic): 1.92e-25
Time: 14:36:13 Log-Likelihood: -322.88
No. Observations: 100 AIC: 649.8
Df Residuals: 98 BIC: 655.0
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 2.2501 1.394 1.614 0.110 -0.517 5.017
x1 -3.2131 0.227 -14.162 0.000 -3.663 -2.763
==============================================================================
Omnibus: 1.152 Durbin-Watson: 2.282
Prob(Omnibus): 0.562 Jarque-Bera (JB): 1.071
Skew: -0.249 Prob(JB): 0.585
Kurtosis: 2.904 Cond. No. 14.2
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
The output provides information about the model. The main things to focus on are the coefficient estimates for const and x1. For each coefficient, we see:
The coefficient estimate,
coef. The estimates here match what we calculated above.The standard error of the estimate,
std err. This is the standard deviation of our estimate. The estimate itself is a random variable, so it has a distribution. If we could run this regression on different data repeatedly, \(\hat\beta\) would vary across samples. But how much would it vary? The standard error gives an estimate of the standard deviation of that distribution. The smaller is the standard error, the more precise is our estimate, and the more confident we are that the estimate is close to the true value.The t-statistic,
t. This is simplycoefdivised bystd err. It tells us how many standard deviations from zero is the coefficient estimate. The more standard deviations from zero is the coefficient, the more confident we can be that the coefficient is not zero (and that the coefficient should therefore be included in our model). Recall that 95% of a Normal pdf lies within 1.96 standard deviations of the mean, so a conventional cutoff value to determine that a result is statistically significant is 1.96. To be even more sure, we could use a cutoff of 2.58, corresponding to a 99% confidence level.The p-value,
P>|t|. This is the probability that, under the null hypothesis that \(\beta=0\), we would see a coefficient estimate as large ascoef. In other words, it is the probability of getting this coefficient estimate even if the true coefficient is zero. The smaller this number is, the more confident we can be that the true value of the coefficient is not zero. Conventional cutoff values for this value are 0.05 or 0.01, meaning we have only a 5% or a 1% chance of incorrectly getting a non-zero estimate. For technical statistical reasons, the \(p\)-values are calculated from the \(t\)-distribution with parameter \(\nu\) equal to the \(N-K\), shown inDF Residuals. As long as this is reasonably large (say, about 100), it is very close to a Normal distribution.The 95% confidence interval, with a 2.5% lower bound (
0.025) and the 97.5% upper bound (0.975). This gives the lower and upper bound for the range in which we expect the true value of \(\beta\) to lie, in 95% of samples. If this range includes zero, we cannot be 95% confident that the true coefficient is not zero.
Note that the \(t\)-statistic, \(p\)-value, and confidence intervals each provide a different way of determining the same thing — whether the coefficient estimate is statistically significant, meaning we are confident that it is not zero. If we do not have significant statistical evidence that the coefficient is not zero, we will not reject the null hypothesis, and must conclude that the true coefficient may be zero. (The assumption here is that the null hypothesis for the coefficient values are zero. We might choose a different null hypothesis depending on the economic meaning of the regression we are running. For example, a reasonable null hypothesis for the \(\beta\) coefficient in a CAPM regression, which we will discuss later, is that it equals one.)
All of the values reported here are available as properties of the results object.
# coefficient (a.k.a. "parameter") estimates
results.params
array([ 2.25006151, -3.21306049])
# standard errors
results.bse
array([1.39446419, 0.22687479])
results.tvalues
array([ 1.61356708, -14.16226327])
results.pvalues
array([1.09836933e-01, 1.91579434e-25])
results.conf_int()
array([[-0.51720728, 5.0173303 ],
[-3.66328612, -2.76283485]])
The \(R^2\), reported in the top right, matches what we saw previously for these data. (The adjusted \(R^2\) makes a small adjustment for now many regressors are in the model.)
results.rsquared
0.6717684356677902
The residuals in the model, \(y_i - \hat y_i\), are stored in results.resid.
results.resid
array([ -5.91397468, 5.07665738, -6.98873 , -4.77994096,
0.49220215, -3.96302479, -0.01640861, 0.62167248,
-8.93456945, 4.75380849, -3.38790079, 0.59063684,
0.56155237, 6.58183194, -3.48127291, 10.05438448,
3.67793934, 3.3280935 , 9.33665701, 4.38616836,
11.25593172, 2.368698 , -3.61804042, -2.92435415,
-0.68969778, -1.83603276, 0.06247803, 0.53630417,
7.08035302, -6.39939944, 2.32779418, -1.08186821,
0.83827227, 3.80096487, -0.13286615, -11.63278491,
12.78918804, 8.64175088, -6.59585822, 3.59027232,
-4.88406231, 0.86884297, -9.46777888, 8.00687785,
-5.67446301, -1.42314026, -1.11552602, 3.18585992,
6.33387461, 2.61309851, -2.83416709, 10.72126541,
-3.97561675, 4.27015649, 3.15769668, 6.44483539,
9.20391077, -6.29658009, -2.62055196, 1.77883887,
-15.65130528, 5.09749229, 4.16405288, -3.27092355,
8.5428581 , -12.64911823, 2.86861065, 6.95307436,
-10.06853904, -1.50939294, 7.99126133, 6.48402135,
-2.77350482, -0.63466593, -0.91844545, 3.6306765 ,
-8.48031017, 1.25470168, 9.84338626, -0.11856589,
-5.05016436, 1.82615412, -1.07633402, -0.80554071,
-4.67484153, -14.99787183, -2.79584693, 5.60637308,
-6.34644129, 0.32560137, -15.13062335, -4.25759084,
-8.11142115, -2.16412499, 1.60561356, 2.57238982,
1.67443057, -4.37752497, 11.98568519, -5.23354454])
Notice also that the skewness and kurtosis of the residuals, reported on the bottom left of the summary table, match what we would expect for a Normally distributed random variable.
import scipy.stats as scs
scs.skew(results.resid)
-0.24898612136624373
scs.kurtosis(results.resid) + 3
2.9041857964065585
We can calculate predicted values for values of \(x\) from using the results.predict method. Here, we’ll use our model to predict data for \(x={-3, -2, \ldots, 12}\).
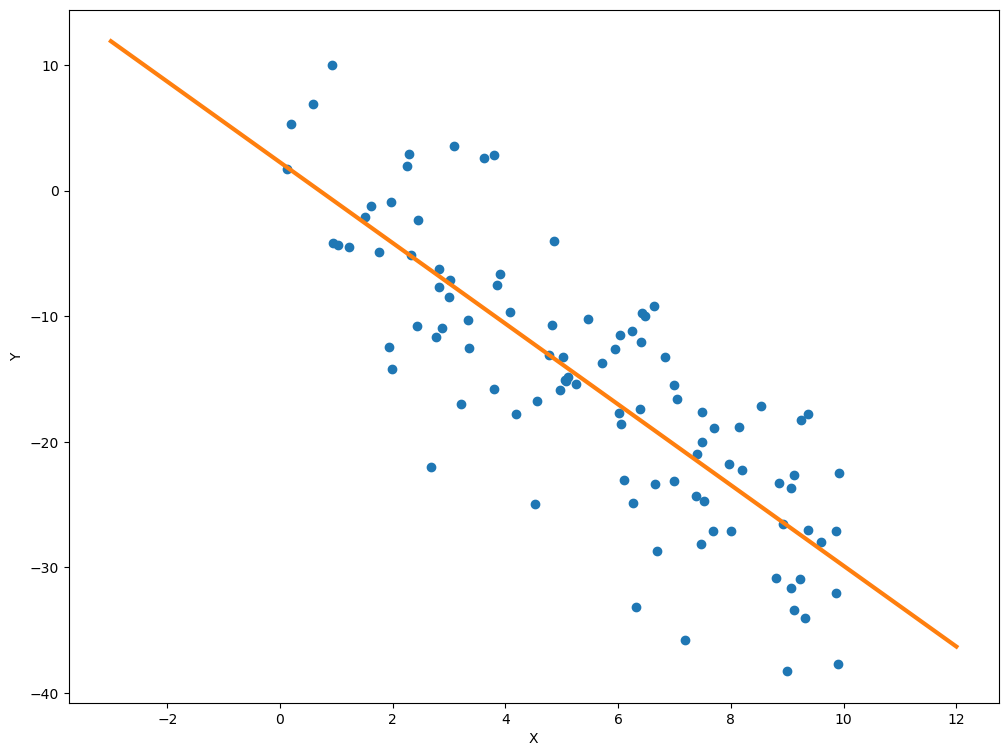
sklearn#
Scikit-learn is a module that provides extensive capabilities for machine learning (ML). Since linear regression is one of the tools of ML methods, it is included among many other types of models.
from sklearn.linear_model import LinearRegression
# easier to work with a 1-dimensional array in sklearn
y = np.squeeze(y)
lin_reg = LinearRegression()
lin_reg.fit(x, y) # note that we don't pass the X matrix augmented with 1s
LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| fit_intercept | True | |
| copy_X | True | |
| tol | 1e-06 | |
| n_jobs | None | |
| positive | False |
Again, the coefficient estimates are identical to the previous methods.
lin_reg.intercept_
2.250061509500279
lin_reg.coef_
array([-3.21306049])
# R-squared
lin_reg.score(x,y)
0.6717684356677902
Standard errors and t-statistics#
sklearn doesn’t give standard errors but we can calculate them. We simply use the equation for the variance-covariance matrix of the coeffient estimates,
The diagonal elements of this matrix give the estimated variance of each coefficent, which we can use to calculate the standard errors. The calculated values are very similar to the statsmodels results, but vary slightly due to different statistical assumptions embedded in the calculation.
n, k = X.shape
resid = y - lin_reg.predict(x)
s2 = (resid @ resid) / (n - k)
varcov = s2 * np.linalg.inv(X.T @ X)
varcov
array([[ 1.94453037, -0.28369398],
[-0.28369398, 0.05147217]])
se = np.sqrt(np.diag(varcov))
se
array([1.39446419, 0.22687479])
np.array([lin_reg.intercept_, lin_reg.coef_[0]]) / se
array([ 1.61356708, -14.16226327])
Nonlinear data#
What if our data isn’t linear? We can explore an example by changing how \(y\) is generated.
x = 6 * rng.uniform(size=(N,1)) - 3
y = 2 + x + 0.5*x**2 + rng.standard_normal(size=(N, 1))
fig, ax = plt.subplots(figsize=(12,6))
ax.plot(x, y, 'bo')
ax.set_xlabel('x', fontsize=16)
ax.set_ylabel('y', rotation=0, fontsize=16)
ax.axis([-3, 3, 0, 10])
plt.show()
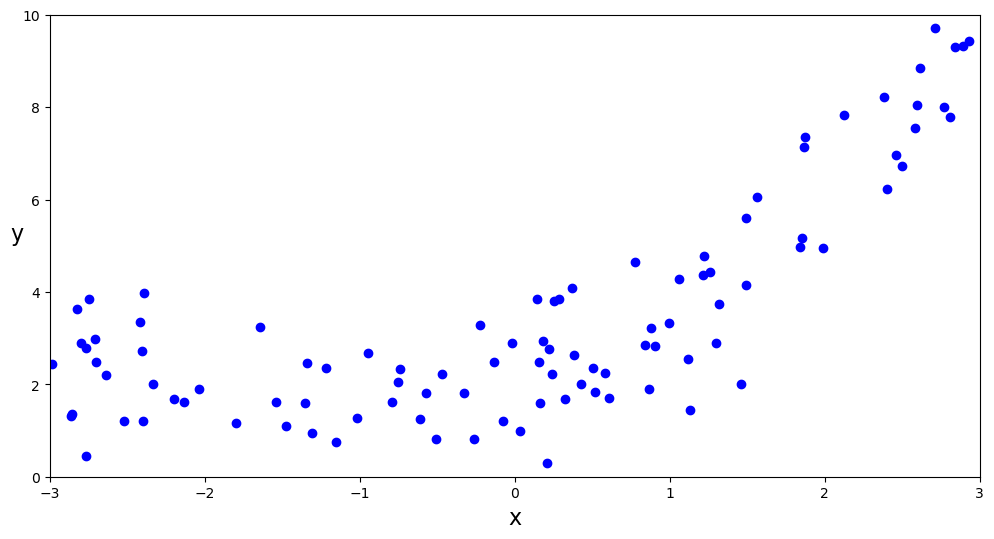
Since the data look nonlinear, let’s add a higher order term to the regression. Specifically, we’ll add \(x^2\) to the design matrix.
X = np.c_[np.ones(N), x, x**2]
X[:5]
array([[ 1. , 0.86551968, 0.74912432],
[ 1. , -1.33982714, 1.79513677],
[ 1. , -1.35113649, 1.82556983],
[ 1. , 2.89001064, 8.3521615 ],
[ 1. , -0.57339857, 0.32878593]])
Now we just estimate the regression as before.
model2 = sm.OLS(y, X)
results2 = model2.fit()
print(results2.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.825
Model: OLS Adj. R-squared: 0.822
Method: Least Squares F-statistic: 229.1
Date: Tue, 17 Feb 2026 Prob (F-statistic): 1.80e-37
Time: 14:36:19 Log-Likelihood: -140.79
No. Observations: 100 AIC: 287.6
Df Residuals: 97 BIC: 295.4
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 2.0611 0.145 14.201 0.000 1.773 2.349
x1 1.0753 0.058 18.508 0.000 0.960 1.191
x2 0.4504 0.035 13.048 0.000 0.382 0.519
==============================================================================
Omnibus: 1.062 Durbin-Watson: 2.065
Prob(Omnibus): 0.588 Jarque-Bera (JB): 1.153
Skew: -0.195 Prob(JB): 0.562
Kurtosis: 2.646 Cond. No. 6.30
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Now it’s easy to see what the prediction line looks like.
y_hat = np.asarray(results2.predict(X)).reshape(-1)
fig, ax = plt.subplots(figsize=(12,6))
x_flat = x[:, 0]
y_flat = y[:, 0]
order = np.argsort(x_flat)
b0, b1, b2 = results2.params
eqn = f'$\\hat{{y}} = {b0:.2f} + {b1:.2f}x + {b2:.2f}x^2$'
ax.plot(x_flat, y_flat, 'bo')
ax.plot(x_flat[order], y_hat[order], 'r-', lw=3)
ax.set_xlabel('x', fontsize=16)
ax.set_ylabel('y', rotation=0, fontsize=16)
ax.axis([-3, 3, 0, 10])
ax.text(0.02, 0.95, eqn, transform=ax.transAxes, ha='left', va='top', fontsize=16, color='red')
plt.show()
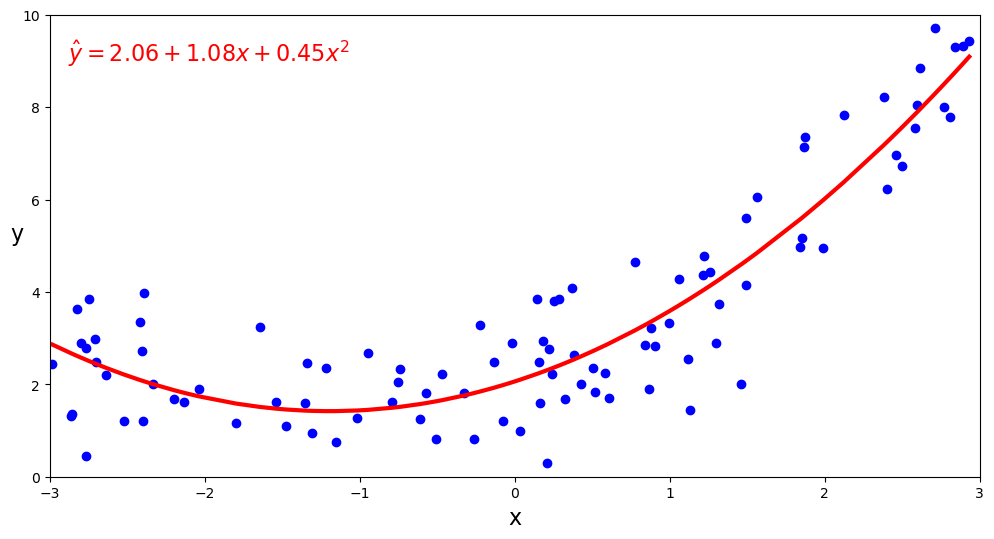
Exercise
Add a third regressor to this estimation, \(x^3\), and re-estimate the regression. Do the estimates make sense?
In scikit-learn we can easily add additional polynomial terms.
from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree=2)
x_poly = poly_features.fit_transform(x)
x_poly[:5]
array([[ 1. , 0.86551968, 0.74912432],
[ 1. , -1.33982714, 1.79513677],
[ 1. , -1.35113649, 1.82556983],
[ 1. , 2.89001064, 8.3521615 ],
[ 1. , -0.57339857, 0.32878593]])
lin_reg2 = LinearRegression(fit_intercept=False)
lin_reg2.fit(x_poly, y)
lin_reg2.coef_
array([[2.06114078, 1.07527261, 0.45043034]])
poly_features = PolynomialFeatures(degree=4)
x_poly = poly_features.fit_transform(x)
lin_reg2.fit(x_poly, y)
lin_reg2.coef_
array([[ 2.06825355, 0.83379512, 0.4774944 , 0.04102555, -0.00357288]])