
%load_ext autoreload
%autoreload 2
from helper_functions import display_matrix
Efficient portfolios#
Suppose we wish to find
Here, \(\mathbf{1} = (1, \ldots, 1)'\) is an \(N\)-vector of ones. We’ll also define \(\boldsymbol{\mu} = (\mu_1, \cdots, \mu_N)'\) to be the vector of expected returns for the assets. I am following the convention that boldface indicates a vector or matrix, while scalars are in regular font.
For reasons that will soon become clear, let’s first define the following scalars:
Each of these is the product of a \(1\times N\) vector, an \(N\times N\) matrix, and an \(N\times 1\) vector, so the result has dimension \(1\times 1\): that is, just a scalar. Note that since these are scalars, \(B'=B\), so \(\mathbf{1}'\boldsymbol{\Sigma}^{-1}\boldsymbol{\mu} = \boldsymbol{\mu}'\boldsymbol{\Sigma}^{-1} \mathbf{1}.\)
Notice also that \(C\) is simply the sum of all of the elements of \(\bsi\).
This is a constrained optimization problem that can be solved using the method of Lagrange multipliers. The solution is
Extra credit
To solve the problem, we write the Lagrangian
where \(\lambda\) is the Lagrange multiplier. Then, we set the derivative equal to zero and solve for the optimal weights:
We can find the value of \(\lambda\) by substituting this back into the constraint:
Therefore, \(\lambda = \frac{1}{C},\) which gives the expected result:
These weights generate the portfolio with the minimum possible variance. The variance of this portfolio is
To develop some intuition for what these values mean, let’s consider the simplest case of two assets.
where \(\Delta = \sigma_1^2\sigma_2^2 - \sigma_{12}^2\) is the determinant of \(\bs\).
Then
So the final expression is:
The weights on the two assets in the GMV are therefore:
You shouldn’t be surprised that these exactly match what we found earlier in equations (13) and (14).
The numerator captures the risk of the other asset, adjusted for covariance. If asset 2 has high variance, that makes you want more of asset 1 (since \(\omega_1\) increases with \(\sigma_2^2\)). If the assets are strongly positively correlated (large \(\sigma_{12}\)), that reduces diversification benefits, so the weight on asset 1 falls. That is, you invest more in the asset that diversifies better.
The denominator captures the total portfolio variance potential. It’s essentially the variance of a portfolio that’s half in each asset without scaling. It ensures that weights sum to one and normalize by overall risk trade-offs.
Consider also some limiting cases. With perfect correlation, \(\sigma_{12} = \sigma_1\sigma_2\), and the denominator goes to zero: there’s no diversification. The GMV portfolio is undefined (since any linear combination has the same variance). On the other hand, with zero correlation, \(\omega_1^{\text{GMV}} = \frac{\sigma_2^2}{\sigma_1^2+\sigma_2^2}\). This means you put less weight on the riskier asset — weights are inversely proportional to variances.
When all \(N\) assets have variance \(\sigma^2\) and common pairwise correlation \(\rho\), the covariance matrix is
where \(I_N\) is the \(N\times N\) identity matrix and \(J_N\) is the \(N\times N\) all-ones matrix, \(J_N := \mathbf{1}\mathbf{1}'\).
In this case, we can show that the GMV portfolio collapses to the equal-weighted portfolio,
and
Extra credit
To see this, define
and note that:
\(P\) and \(Q\) are both idempotent, so \(P^2 = P\) and \(Q^2 = Q\). They are also symmetric, so \(P'=P\) and \(Q'=Q\). Together, these facts mean that \(Q\) and \(P\) are orthogonal projection matrices.
It follows that \(PQ = 0\).
The sum of the elements of each column of \(Q\) is zero, so \(Q\mathbf{1} = \mathbf{0}\).
The sum of the elements of each column of \(P\) is 1, so \(P\mathbf{1} = \mathbf{1}\).
\(Q + P = I_N\).
\(N\times P = J_N\).
We can now write \(\bs\) in terms of \(P\) and \(Q\):
Set \(a := 1 - \rho + \rho N = 1 + \rho(N - 1)\), so
Because \(Q\) and \(P\) are orthogonal projection matrices, it is trivial to invert them:
(You can check \(\bs \bsi = I\) by using \(Q^2 = Q\), \(P^2 = P\), \(PQ = 0\), and \(Q + P = I\).) Therefore,
But \(Q\mathbf{1} = 0\) and \(P\mathbf{1} = \mathbf{1}\), so
Now,
Using \(Q\mathbf{1} = \mathbf{0}\) and \(P\mathbf{1} = \mathbf{1}\), it follows that \(\mathbf{1}'Q\mathbf{1} = 0\) and \(\mathbf{1}'P\mathbf{1} = \mathbf{1}'\mathbf{1} = N\), so
The weights of the GMV portfolio are therefore
which are simply the weights for the equal-weighted portfolio. We can also calculate the portfolio variance:
The variance decomposes into the idiosyncratic piece \(\sigma^2/N\) plus the common component \(\rho\sigma^2 (N-1)/N\); as \(N\to\infty\), the idiosyncratic part vanishes and the GMV variance approaches \(\rho\sigma^2\).
Writing this differently,
For a fixed \(N\) and \(\rho>0\), the variance is a correlation-weighted average of the undiversifiable risk \(\sigma^2\) and a diversifiable part, \(\sigma^2/N\).
The expected return on the GMV portfolio is
Exercise
Use the 2-asset example from earlier, with
Calculate the values of:
\(\bs\)
\(\bsi\)
the weights of the GMV portfolio.
Confirm that the expected return and variance of the GMV portfolio can be calculated using \(B\) and \(C\) as above.
Solution
μ = np.array([0.1, 0.2])
σ1, σ2, ρ = 0.2, 0.3, 0.2
# Calculate Σ matrix
σ12 = ρ * σ1 * σ2
Σ = np.array([[σ1**2, σ12],
[σ12, σ2**2]])
print(f'Σ:\n {Σ}')
from numpy.linalg import inv
Σinv = inv(Σ)
print(f'Σinv:\n {Σinv}')
w = Σinv @ np.ones(2) / C
print(f'w: {w}')
# Expected return of the GMV portfolio
print(f'Expected return: {w @ μ}')
B = μ.T @ Σinv @ np.ones(2)
C = np.ones(2).T @ Σinv @ np.ones(2)
print(f'B/C: {B/C}')
# Volatility of the GMV portfolio
print(f'Volatility: {np.sqrt(w @ Σ @ w)}')
print(f'sqrt(1/C): {np.sqrt(1/C)}')
Risk-adjusted returns#
Suppose instead that an investor wishes to maximize the risk-adjusted return. She likes return, so wants as much of that as possible; but she dislikes risk and wants as little of that as possible. How much does she dislike riks? It depends on her level of risk aversion. We’ll suppose that we can summarize this risk aversion with a parameter \(\gamma\).
–> ADD utility function
In this case, the investor’s problem is
This is a constrained optimization problem that can be solved using the method of Lagrange multipliers. The solution is
where the constant \(\lambda\) is defined as
We can then write the weights as follows:
The portfolio weights are a linear combination of two terms:
\(\frac{1}{\gamma}\boldsymbol{\Sigma}^{-1}\boldsymbol{\mu}\)
\(\frac{\boldsymbol{\Sigma}^{-1}\mathbf{1}}{C}\), which we already saw is the weights of the GMV portfolio.
The weight on the first term is \(\frac{1}{\gamma}\) and the weight on the second is \(1-\frac{B}{\gamma}\).
Notice that as \(\gamma\) gets large, the first term vanishes and the weight on the GMV term approaches 1, so a very risk-averse investor simply holds the GMV portfolio.
When \(\gamma = B\), the weight on the GMV term is \(1 - B/B = 0\), and the portfolio is proportional to \(\boldsymbol{\Sigma}^{-1}\boldsymbol{\mu}\). This turns out to be the tangency portfolio, which we will study below. When \(\gamma > B\), the optimal portfolio is a blend of the tangency portfolio and the GMV portfolio, with more weight on the GMV portfolio as risk aversion increases.
Extra credit
Following the same steps above, the Langrangian is
where \(\gamma\) and \(\lambda\) are the Lagrange multipliers. Setting the derivative equal to zero, we have
so
To find the value of \(\lambda\), we can use the constraint:
so, solving for \(\lambda\),
Comparing to the solution above, we can see that the weights here are the same, where the constants are related by
Alternative setup: Minimizing risk#
Another approach is to find efficient portfolios that have minimum risk (variance) for a given level of return \(\mu_p\). We can find these by choosing \(\omega\) to solve
This problem simply says to select weights that will create a portfolio with an expected return of \(\mu_p\) and has the lowest possible variance; the last condition implies that the portoflio must be fully invested with its weights adding up to one.
This can be solved directly using the method of Lagrange multipliers, which gives the solution
where, for convenience, we have defined the scalars
(Since \(B\) is just a scalar, \(B=B'\), and we can ignore the transpose.)
Extra credit
To solve a constrained optimization using the method of Lagrange multipliers, we form the Lagrangian function that combines the function we seek to minimize along with the constraints. Each constraint is multiplied by an unknown constant, called a Lagrange multiplier. In our case, defining \(\lambda\) and \(\delta\) as the two Lagrange multipliers, we have
I’m also using the trick of multiplying the variance by \(\frac{1}{2}\) because I know that the derivative of a quadratic form will be multiplied by 2 and I want it to disappear. Obviously, the \(x\) that minimizes \(f(x)\) will also minimize \(\frac{1}{2}f(x)\).
Then we proceed as ususal, differentiating with respect to \(\boldsymbol{\omega}\) and setting equal to zero. The derivative is
Notice that this is exaclty as above…
and setting this equal to zero yields the optimal solution for the weights:
Next, we solve for the Lagrange multipliers, \(\lambda\) and \(\delta\). First, since \(\boldsymbol{\Sigma}\) is symmetric, \(\boldsymbol{\Sigma}^{-1}\) is also symmetric, and \(\left(\boldsymbol{\Sigma}^{-1}\right)' = \boldsymbol{\Sigma}^{-1}\). Therefore, using the fact that \((AB)' = B'A'\),
Substituting this expression for the weights into the first constraint gives
and into the second constraint:
Combining these, we have
which we can simplify by collecting terms:
Solving for the unknowns, we have
We can then substitute these into the solution for the weights above, which gives
as shown in the main text.
Note that \(\mathbf{1}'\boldsymbol{\Sigma}^{-1} \boldsymbol{\mu}\) is the same as \(\boldsymbol{\mu}'\boldsymbol{\Sigma}^{-1}\mathbf{1}\), since one is just the transpose of the other, and the transpose of a scalar is just itself.
Recall that the inverse of a simple \(2\times 2\) matrix is
Applying this formula to the matrix with these scalars and simplifying, we get
Using these weights we can find the variance of an efficient portfolio as
This is a quadratic equation in \(\mu_p\). Since the square-root of a parabola is a hyperbola, the efficient frontier is a hyperbola in mean–standard deviation space.
Estimating the frontier#
Let’s apply these formulas to some real data.
rets = pd.read_csv('https://raw.githubusercontent.com/stoffprof/qf_data/main/country_returns.csv',
index_col='Date', parse_dates=['Date'])
# Move the dates to the end of each month
rets.index = rets.index + pd.offsets.MonthEnd(0)
rets.info(verbose=False)
Returning to the problem of optimal portfolio formation, we can apply our formulas directly to the estimated covariance and expected returns from the data.
from numpy.linalg import inv
# store mean and covariance matrix as numpy arrays
μ = np.array(rets.mean())
Σ = np.array(rets.cov())
N = len(μ)
Σinv = inv(Σ)
A = μ.T @ Σinv @ μ
B = μ.T @ Σinv @ np.ones(N)
C = np.ones(N).T @ Σinv @ np.ones(N)
print(A, B, C)
0.12061234125066467 2.333199380149395 917.9215084683982
Exercise
Verify that \(C\) is simply the sum of the elements of \(\Sigma^{-1}\).
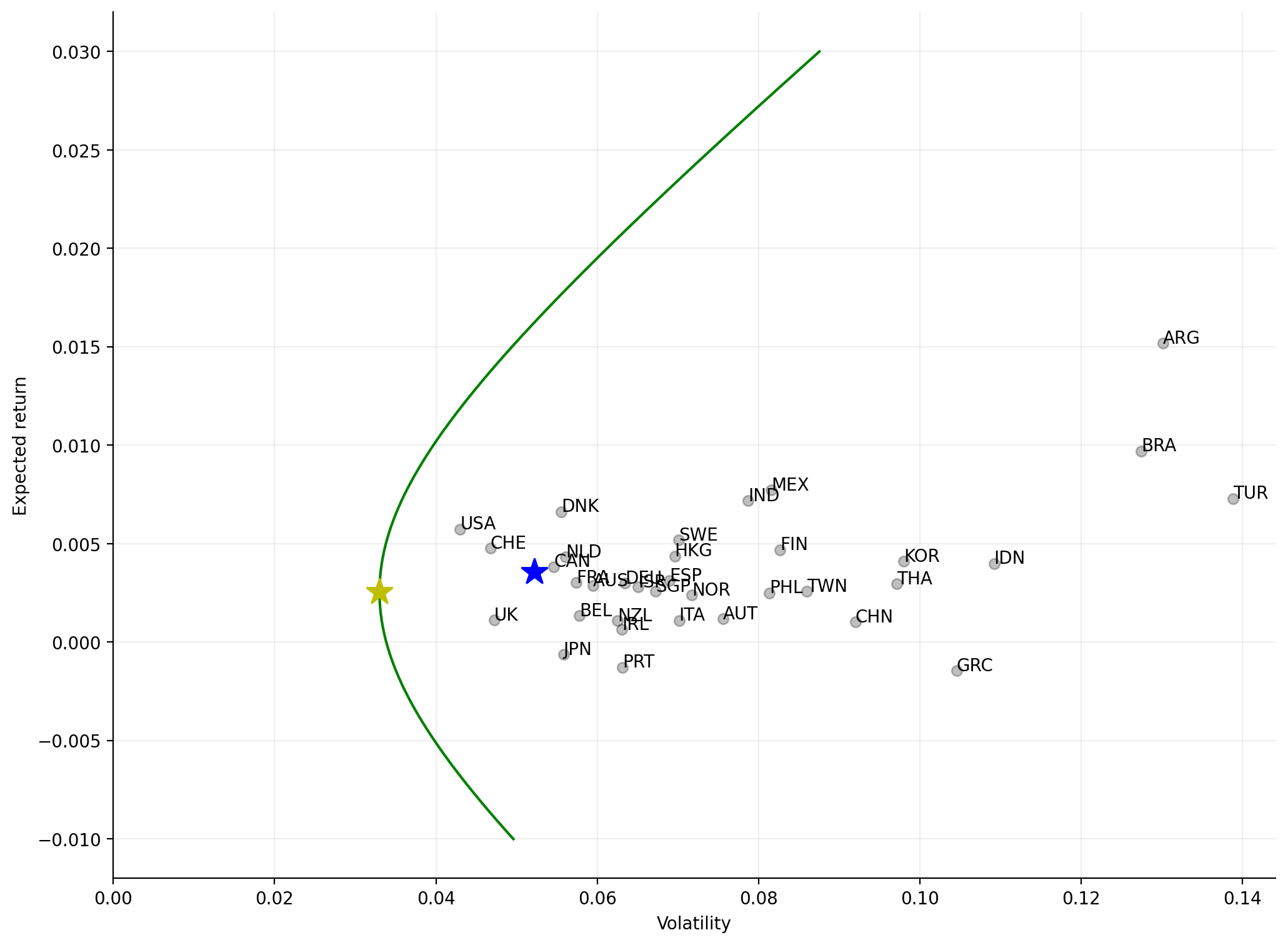
The global minimum variance portfolio#
The variance of an efficient portfolio is a function of the target return, \(\mu_p\). We can minimize this function to find the portfolio with minimum possible variance:
That is, the global minimum variance portfolio (“GMV”) has an expected return of \(B/C\). Substituting this into the solution for optimal weights,
implying that the variance is
In volatility–return space, then, the GMV is at \(\left(\sqrt{\frac{1}{C}}, \frac{B}{C}\right)\).
The tangency portfolio#
The Sharpe ratio is a measure of reward-to-risk: how much return do we get per unit of volatility. It’s calculated as
The portfolio with the maximum possible Sharpe ratio is called the tangency portfolio.
For an efficient portfolio with expected excess return \(\mu_p\), the Sharpe ratio is
To find the portfolio with the maximum possible Sharpe ratio, we want to choose the value of \(\mu_p\) that maximizes this function. Therefore, we differentiate with respect to \(\mu_p\), set the result equal to zero, and solve for \(\mu_p\), which gives:
This, then, is the expected return on the tangency portfolio. To find the portfolio’s volatility, we first substitute into equation (15) to find the weights of the tangency portfolio, which are given by
The variance of the tangency portfolio is therefore
so in volatility–expected return space, the portfolio is located at at \(\left(\frac{\sqrt{A}}{B}, \frac{A}{B}\right)\). Its Sharpe ratio is therefore
plot_frontier(rets)
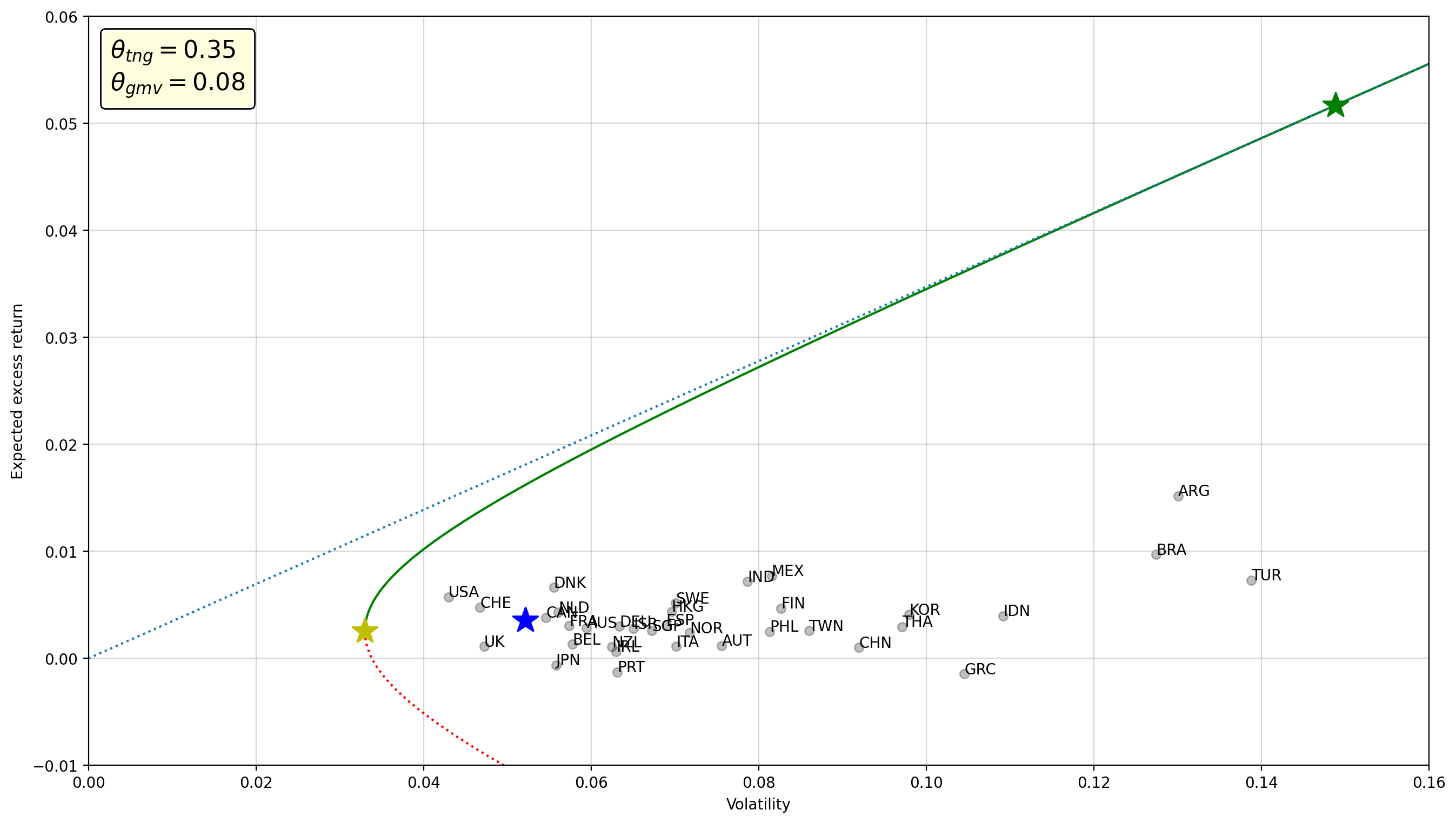
Check your understanding
Is the Sharpe ratio of a portfolio shown on this graph? Where can we see the Sharpe ratio for the tangency portfolio?
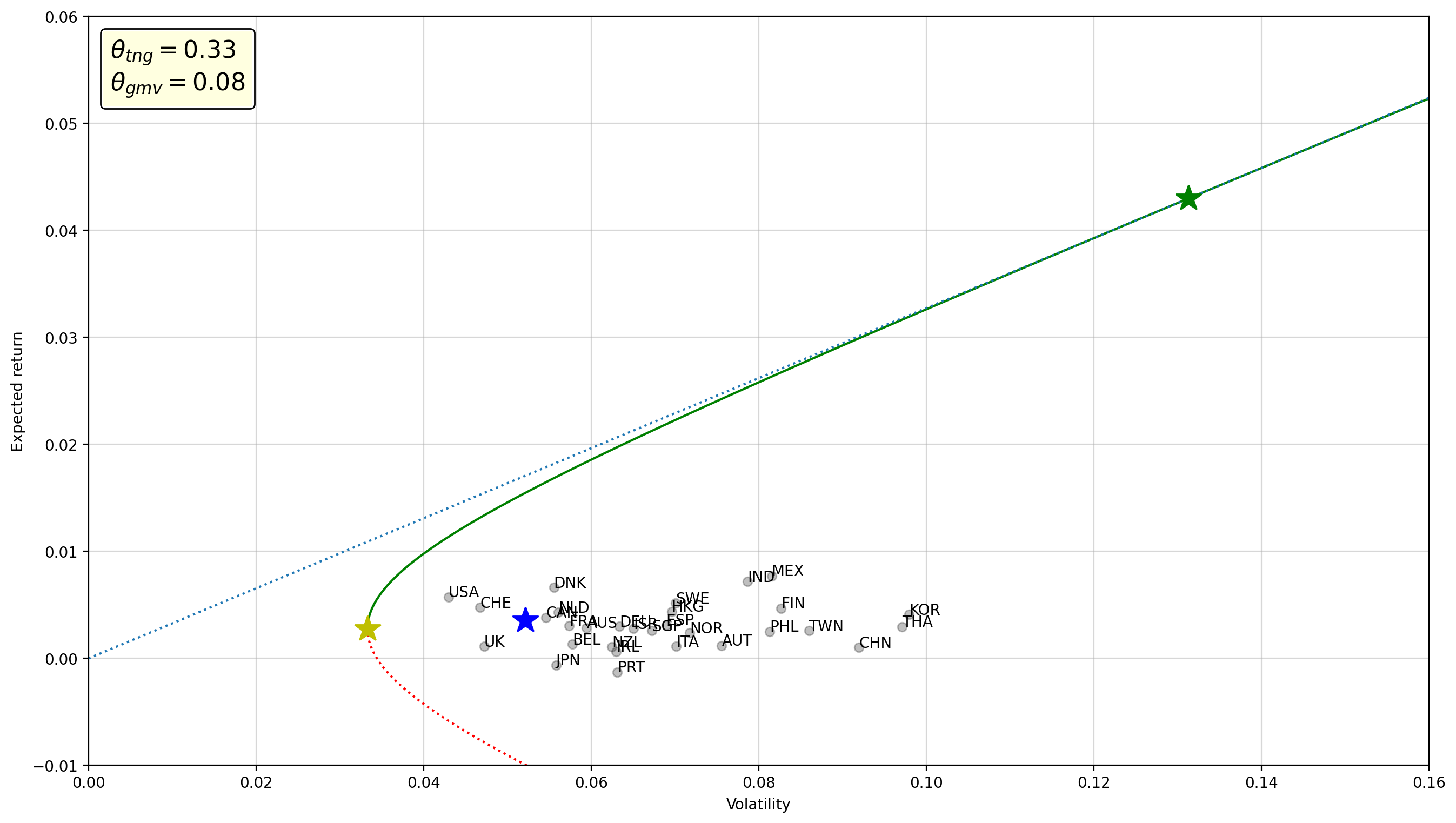
Since we created a function to make this chart, it’s easy to see how altering the set of countries in the investment opportunity set changes the result.
plot_frontier(rets.drop(columns=['Turkey', 'Brazil', 'Argentina', 'Greece', 'Indonesia']))
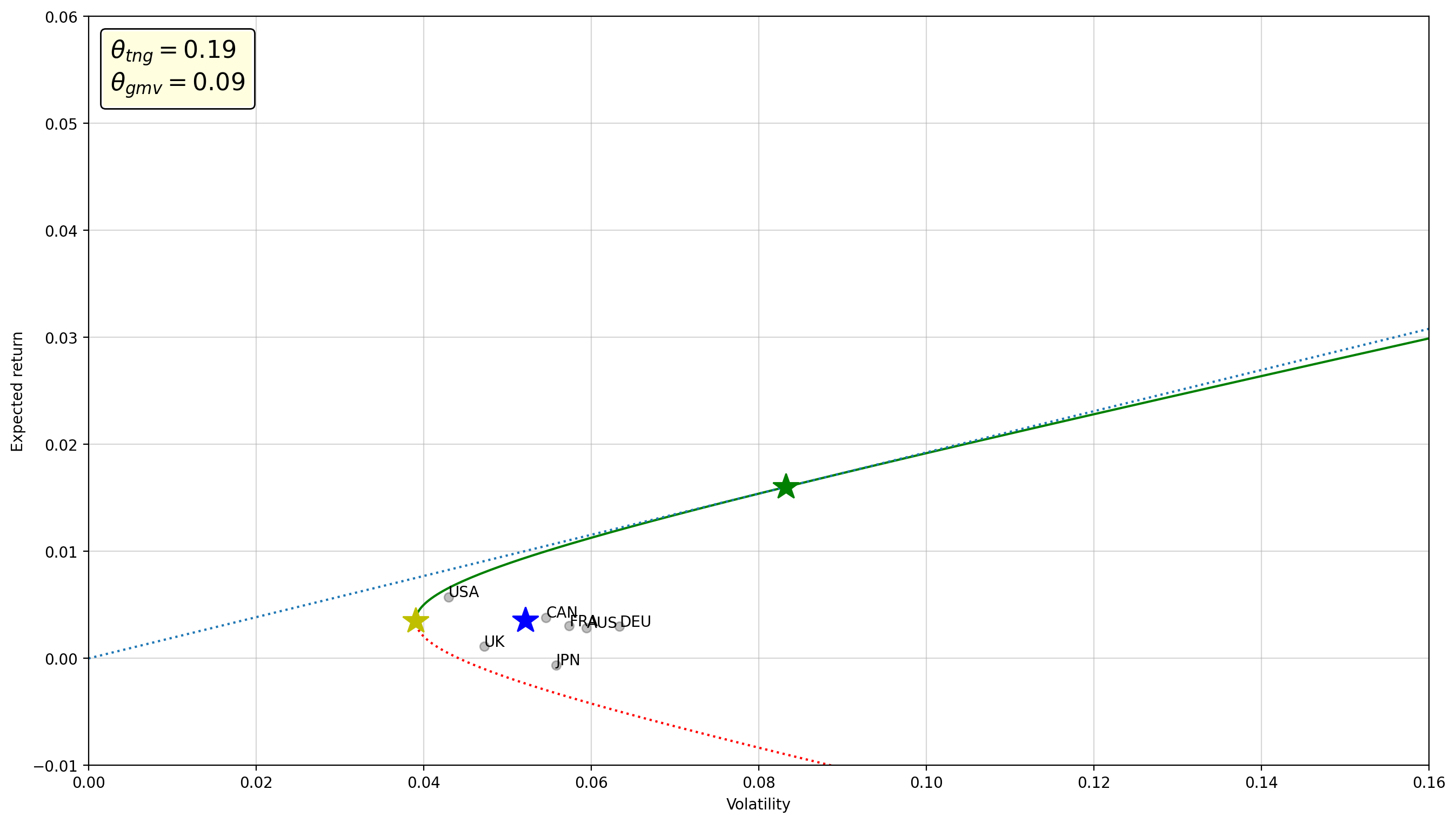
plot_frontier(rets[['USA', 'United Kingdom', 'Canada', 'Germany', 'France', 'Australia', 'Japan']])
Relationships between the TNG, GMV, and EW portfolios#
As we saw above, the weights of the tangency portfolio are
If we assume that all assets have the same expected return, \(\mu\), then the vector of returns is
The weights therefore become
That is, the GMV portfolio is equivalent to the tangency portfolio if we assume that all expected returns are the same.
Next, consider the extreme case where all assets are uncorrelated and have the same variance. The covariance matrix is therefore simply
where the common variance is given by the constant \(\sigma^2\). In this case, the weights in the GMV are
That is, the GMV is equivlent to the equal-weighted portfolio in this case.
We can therefore think of the the equal-weighted portfolio as a special case of the global minimum variance portfolio, and the global minimum variance portfolio as a special case of the tangency portfolio. That is,
the EW portfolio requires no estimates of expected returns, covariances, or variances;
the GMV does use information about variances and covariances, but requires no estimates of expected returns; and
the tangency portfolio requires estimates of all three.
The fact that the GMV can be calculated using estimates of only variances/covariances is important because it is actually a lot harder to estimate expected returns than it is to estimate the covariance matrix, as shown by Merton [1980]. We can collect more high-frequency data about returns to get more accurate estimates of variances and covariances, but sampling data with higher frequency does nothing to tell us more about the expected return. All we can do is wait for more time to pass to get more data and improve our estimate of the expected return.
If instead we assume that all assets have the same variance and a single correlation, we can write the variance–covariance matrix like this:
In this case it can be shown that the GMV weights are
Extra credit
To see this relationship, we start with the inverse of this variance–covariance matrix, which can be shown to be
The matrix part simply has \(\rho\) in all the off-diagonal terms, and \(-(N-2)\rho-1\) along the diagonal.
For example, in the \(N=2\) case, this is
Now, to calculate \(\boldsymbol{\Sigma}^{-1}\mathbf{1}\), we know that the result will be an \(N\times 1\) vector where each value is the sum of each row in \(\boldsymbol{\Sigma}^{-1}\). Each of these sums is the same: we have \(N-1\) terms with \(\rho\), plus the \(-(N-2)\rho-1\) term, so every row is
That is,
Now, \(\mathbf{1}'\boldsymbol{\Sigma}^{-1}\mathbf{1}\) is just the sum of these \(N\) values:
Therefore, the GMV weights are
Of course, we need no information about either of the parameters, \(\sigma\) and \(\rho\), to calculate the equal-weight portfolio. So if we assume that these are the only two parameters in the covariance matrix, it no longer matters what they are. Whatever they are, they have no effect on the weights of the GMV, and estimating them becomes irrelevant. We simply end up with the equal-weighted portfolio.
Choosing particular values for \(N\), \(\sigma\), and \(\rho\), we see that the GMV weights are indeed those of an equal-weighted portfolio. Experiment by changing the inputs to see for yourself.
Portfolio weights#
The index weights for the tangency and GMV portfolios are given here:
w_tng = Σinv @ μ / B
w_gmv = Σinv @ np.ones(N) / C
pd.DataFrame({'tng': w_tng,
'gmv': w_gmv},
index=rets.columns).sort_values('tng', ascending=False)
| tng | gmv | |
|---|---|---|
| USA | 2.861860 | 0.609641 |
| Denmark | 1.887925 | 0.131705 |
| Switzerland | 1.748860 | 0.258246 |
| Hong Kong | 0.902527 | 0.020683 |
| Spain | 0.863541 | -0.088113 |
| France | 0.705587 | -0.024290 |
| India | 0.621656 | 0.059804 |
| Netherlands | 0.479715 | -0.233571 |
| Argentina | 0.318018 | -0.005174 |
| Austria | 0.224530 | -0.080220 |
| Turkey | 0.182038 | -0.005140 |
| Australia | 0.176126 | -0.034069 |
| Korea | 0.156850 | -0.068463 |
| Brazil | 0.150849 | -0.038806 |
| Finland | 0.071142 | -0.035367 |
| Mexico | 0.032842 | -0.008054 |
| Sweden | -0.011616 | -0.164743 |
| Thailand | -0.036107 | -0.024262 |
| Singapore | -0.084327 | -0.079599 |
| Indonesia | -0.086577 | -0.006827 |
| Taiwan | -0.170203 | 0.060319 |
| Canada | -0.197325 | -0.034822 |
| Philippines | -0.234042 | 0.042504 |
| Greece | -0.320697 | -0.018502 |
| Norway | -0.336597 | -0.108096 |
| Ireland | -0.364012 | -0.075121 |
| New Zealand | -0.453692 | 0.081240 |
| Italy | -0.517786 | 0.095383 |
| China | -0.565748 | 0.040135 |
| Israel | -0.708202 | 0.091107 |
| Belgium | -0.796391 | 0.059256 |
| Germany | -0.923938 | -0.150510 |
| Japan | -1.048085 | 0.185264 |
| Portugal | -1.390965 | 0.140258 |
| United Kingdom | -2.137757 | 0.408204 |