
U.S. market returns#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import wrds
db = wrds.Connection()
Loading library list...
Done
Any data that we observe at regular intervals over time is a time series. An example could be stock prices or returns. For example, let’s look the S&P 500 index since 2000.
sp500 = db.get_table('crsp', 'dsp500', date_cols=['caldt'], columns=['caldt', 'spindx']).set_index('caldt')
sp500 = sp500.dropna().squeeze()
sp500 = sp500.loc['2000-01-01':]
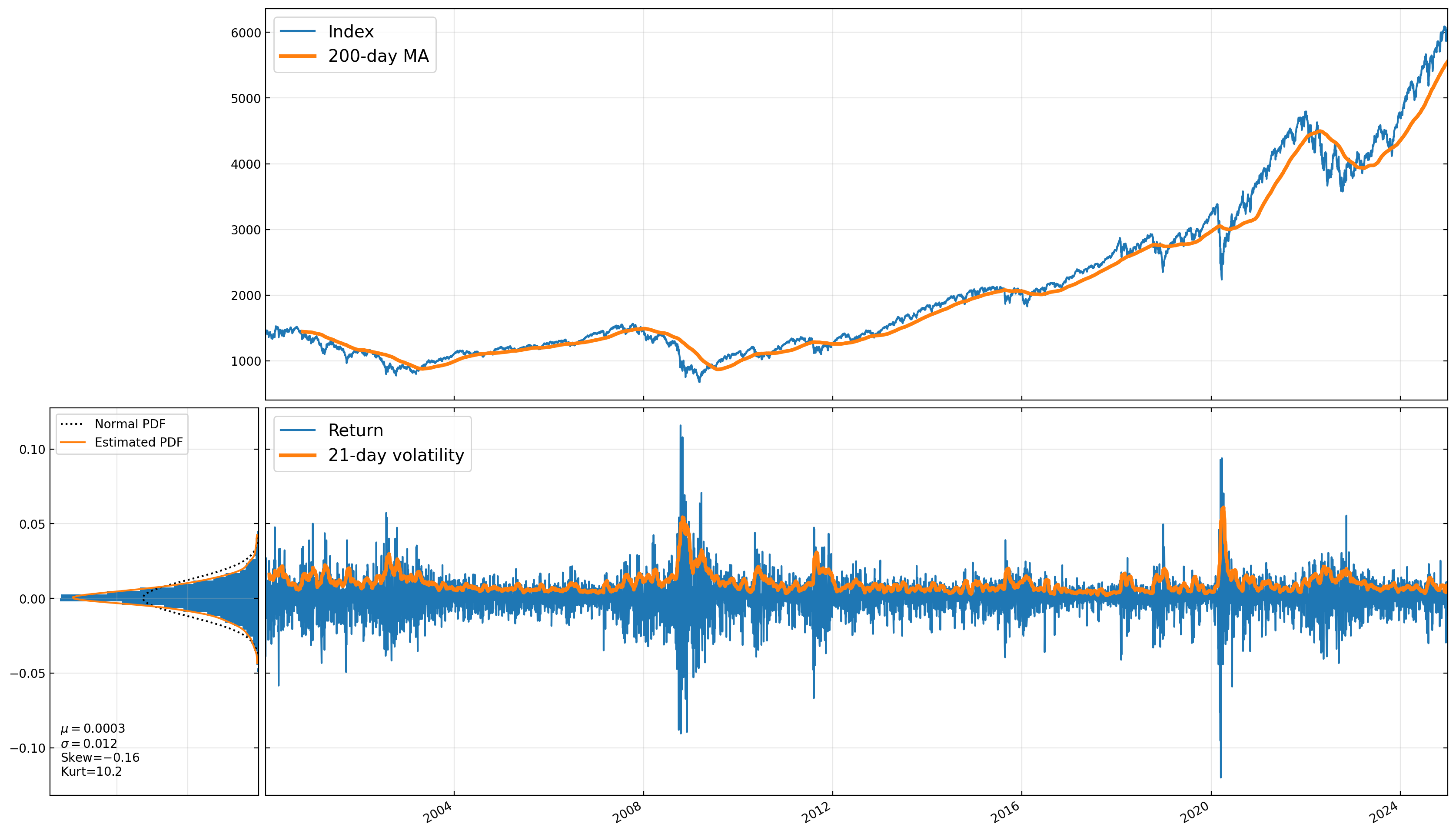
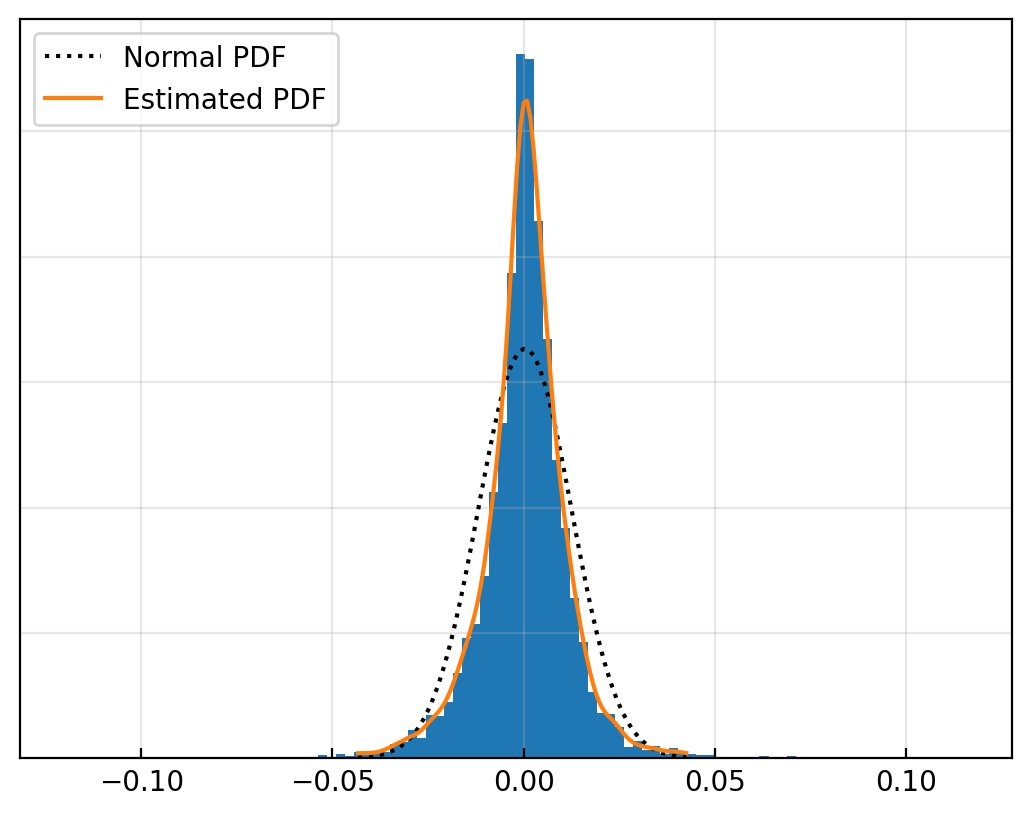
rets = sp500.pct_change().dropna()
# Plot return histogram
ax = rets.hist(bins=100, density=True)
# Add pdf of normal distribution
from scipy.stats import norm, gaussian_kde
μ, σ = rets.mean(), rets.std()
x = np.linspace(rets.quantile(0.005), rets.quantile(0.995), 100)
pdf = norm.pdf(x, μ, σ)
ax.plot(x, pdf, 'k:', label='Normal PDF')
# Kernel density estimation
kde = gaussian_kde(rets.dropna())
ax.plot(x, kde.pdf(x), label='Estimated PDF')
ax.legend(loc='upper left')
ax.tick_params(direction='in', left=False, labelleft=False)
ax.grid(alpha=0.3)
plt.show()
rets.describe()
count 6288.0
mean 0.000297
std 0.012215
min -0.119841
25% -0.004793
50% 0.000597
75% 0.005928
max 0.1158
Name: spindx, dtype: Float64
rets.skew(), rets.kurt()
(-0.16201426750865283, 10.19031755909176)
There are several statistical tests we can use to test the null hypothesis that data are drawn from a normal distribution. Two that are available in scipy are due to D'agostino and Pearson [1973] and the Shapiro and Wilk [1965]. The former combines information about the skewness and kurtosis of a series; the latter is a more complicated test that uses information about order statistics.
Extra credit
To calculate the D’agostino and Pearson test statistic, we calculate the sample mean and standard deviation of the data,
We then calculate the sample skewness and kurtosis:
Next, we make some statistical adjustments to make the skewness and kurtosis statistics normally distributed:
The normalized statistics are then:
Finally, we calculate the \(K^2\) statistic.
This statistic has a \(\chi^2_{(2)}\) distribution under the null hypothesis that the \(X_i\) are drawn from a Normal distribution.
from scipy.stats import normaltest, shapiro
normaltest(rets)
NormaltestResult(statistic=1141.688127847064, pvalue=1.2177917029121804e-248)
shapiro(rets)
/var/folders/8b/3b5yf0214zvg3prfcqs6wx3c0000gq/T/ipykernel_62578/2132643539.py:1: UserWarning: scipy.stats.shapiro: For N > 5000, computed p-value may not be accurate. Current N is 6288.
shapiro(rets)
ShapiroResult(statistic=0.9019364062429657, pvalue=4.684110917502552e-53)