
Numerical optimization#
Rather than using analytical methods to solve the portfolio optimization problem, we can use an algorithm to find the solution numerically.
We’ll begin by reading in the same returns data we used in the previous section.
rets = pd.read_csv('https://raw.githubusercontent.com/stoffprof/qf_data/main/country_returns.csv',
index_col='Date', parse_dates=['Date'])
# Move the dates to the end of each month
rets.index = rets.index + pd.offsets.MonthEnd(0)
# Subtract the risk-free rate
rf = db.get_table('ff', 'factors_monthly', date_cols=['date'], index_col='date')['rf']
rf.index = rf.index + pd.offsets.MonthEnd(0)
rf = rf.loc['1990-02':]
rets = rets.sub(rf, axis=0)
When working with numerical optimization algorithms, it is important that the values being used in a function are not too small. If they are, the rounding error in calculations may be nonneglible relative to the magnitude of the values in the function, and the error can start to swamp the actual information.
An easy solution in these data is simply to multiply by 100, which converts the units to percentage points.
# convert returns to percent
rets = rets * 100
# store parameter estimates in numpy arrays
μ = np.array(rets.mean())
Σ = np.array(rets.cov())
N = len(μ)
# Create an equal-weights vector of N elements
ewgts = np.repeat(1/N, N)
def mvs(weights):
'''Calculate mean, volatility, and Sharpe Ratio for a given set of portfolio weights'''
μp = weights.T @ μ
σp = np.sqrt(weights.T @ Σ @ weights)
return μp, σp, μp/σp
The equal-weighted portfolio has an excess return of 0.36%, volatility of about 5.2%, and a Sharpe ratio of 0.07:
mvs(ewgts)
(0.41826873492330047, 5.164319032501599, 0.08099204024595105)
To implement numerical optimization, we start as before with the minimization problem:
Suppose we want an efficient portfolio with an expected return of 1.2% (per month). Then the target return is
# target return
tret = 1.2
We can use the minimization algorithms in scipy to find us an efficient portoflio (that is, the one that achieves the target return and has minimum variance). To do so, we need to pass the function we want to minimize and the constraints.
import scipy.optimize as sco
Each constraint is entered as dictionary. Since we have two constraints, we’ll pass a list of two dictionaries. Each dictionary has two keys: type indicating whether it is an equality or inequality constraint; and fun that encodes a function representing the constraint. The function must return zero when the constraint is satisfied.
cons = [
# expected return equals target return
{'type': 'eq', 'fun': lambda w: mvs(w)[0] - tret},
# weights sum to one
{'type': 'eq', 'fun': lambda w: np.sum(w) - 1}
]
Next, we’ll define a function that gives the variance of a portfolio given its weights.
def portvar(weights):
return mvs(weights)[1]**2
We’re ready to call the optimization algorithm. We just pass the function to minimize, a starting point for the algorithm (a set of initial weights), and the name of the algorithm we want to use.
p = sco.minimize(portvar, # function to minimize
ewgts, # starting point for variables (weights)
constraints = cons, # constraints
method = 'SLSQP' # minimization algorithm (sequential quadratic programming)
)
The result from calling the minizer is a scipy object that contains information about the solution.
p
message: Optimization terminated successfully
success: True
status: 0
fun: 20.03418572811984
x: [ 5.625e-02 -4.906e-02 ... -1.348e-01 1.014e+00]
nit: 42
jac: [ 4.599e+01 2.315e+01 ... 2.057e+01 2.839e+01]
nfev: 1573
njev: 42
We see the value of the function at its minimum, fun. In our case, this is the value of the minimized variance. The message indicates that the optimization algorithm worked.
The minimization algorithm returns the \(x\) values for the minimized function—in this case, the weights of the efficient portfolio—in the x property of the results object. We can pass that to our mvs() function to get the expected return, variance, and Sharpe ratio of this portfolio.
mvs(p['x'])
(1.1999999999874484, 4.475956403733155, 0.26809912602959957)
Not surprisingly, the expected return of the portfolio is 1.2%; it should be, since one of the constraints we passed the optimizer was that this was the target return. The volatility is 4.476, which matches the square-root of the variance.
We can compare this value to the analytical result from equation (16):
from numpy.linalg import inv
Σinv = inv(Σ)
A = μ.T @ Σinv @ μ
B = μ.T @ Σinv @ np.ones(N)
C = np.ones(N).T @ Σinv @ np.ones(N)
# variance equation
(C * tret**2 - 2*B*tret + A) / (A*C - B**2)
20.034185717662712
This value from the analytical solution is almost identical to the variance calculated with scipy above.
We can also compare the weights from the analytical solution to those found by scipy.
# weights of efficient portfolio using analytical solution
wgts_analytical = Σinv @ ((C*tret-B)*μ + (A-B*tret)*np.ones(N)) / (A*C-B**2)
wgts_analytical
array([ 0.05625378, -0.04906782, 0.00353396, -0.0928659 , 0.00230713,
-0.02624373, -0.08492462, 0.35387646, -0.01090965, -0.01516336,
-0.29585568, -0.07121016, 0.22883116, 0.17138868, -0.04173836,
-0.12706536, -0.05057153, -0.03898678, -0.08430797, 0.01718779,
0.01955091, 0.01474646, -0.05696242, -0.11275671, -0.01132156,
-0.1787043 , -0.08639831, 0.1809275 , -0.12790655, 0.64115697,
0.00307495, -0.03891525, 0.02998854, -0.13482768, 1.01387944])
# Difference between analytical weights and scipy weights
wgts_analytical - p['x']
array([ 7.95764396e-07, -6.69485886e-06, -2.21398086e-06, 6.71659880e-06,
1.51546334e-06, -5.20712426e-06, 3.02334476e-06, 6.66549901e-08,
8.43676374e-07, 1.37560901e-05, -9.08630236e-06, 4.07339046e-06,
-9.74684638e-06, -2.03104490e-06, -1.39167671e-06, 3.11825912e-06,
-2.04028622e-06, 2.58356607e-06, -3.61044853e-06, 2.14625506e-06,
5.18676719e-06, -8.37070106e-06, 1.98250512e-06, -1.23455197e-06,
-3.37090845e-06, 4.69848739e-06, 9.78468426e-06, -1.10840100e-05,
7.43094294e-06, 5.51244587e-06, 1.26551655e-06, -4.30527816e-08,
1.87425472e-06, -7.85788949e-06, -2.39098468e-06])
np.allclose(wgts_analytical, p['x'], atol=1e-4)
True
Clearly, the efficient portfolios found by each method are essentially the same.
The efficient frontier#
To find the efficient frontier, we can sweep across values of \(\mu_p\), and for each one find the portfolio with minimum variance.
# target returns
trets = np.linspace(-1, 3, 50)
tvols = []
for tret in trets:
cons = ({'type': 'eq', 'fun': lambda w: mvs(w)[0] - tret},
{'type': 'eq', 'fun': lambda w: np.sum(w) - 1})
res = sco.minimize(portvar, ewgts, method='SLSQP', constraints=cons)
tvol = np.sqrt(res['fun'])
tvols.append(tvol)
fig, ax = plt.subplots()
# initial portfolios
for i in range(N):
plt.scatter(np.sqrt(Σ[i,i]), μ[i], color='k', alpha=0.25)
# Efficient frontier
ax.plot(tvols, trets, 'g*')
# xmax = np.sqrt(np.diag(Σ)).max() * 1.1
# ymax = μ.max() * 1.1
ax.set_xlim(0, None)
ax.grid(alpha=0.2)
plt.show()
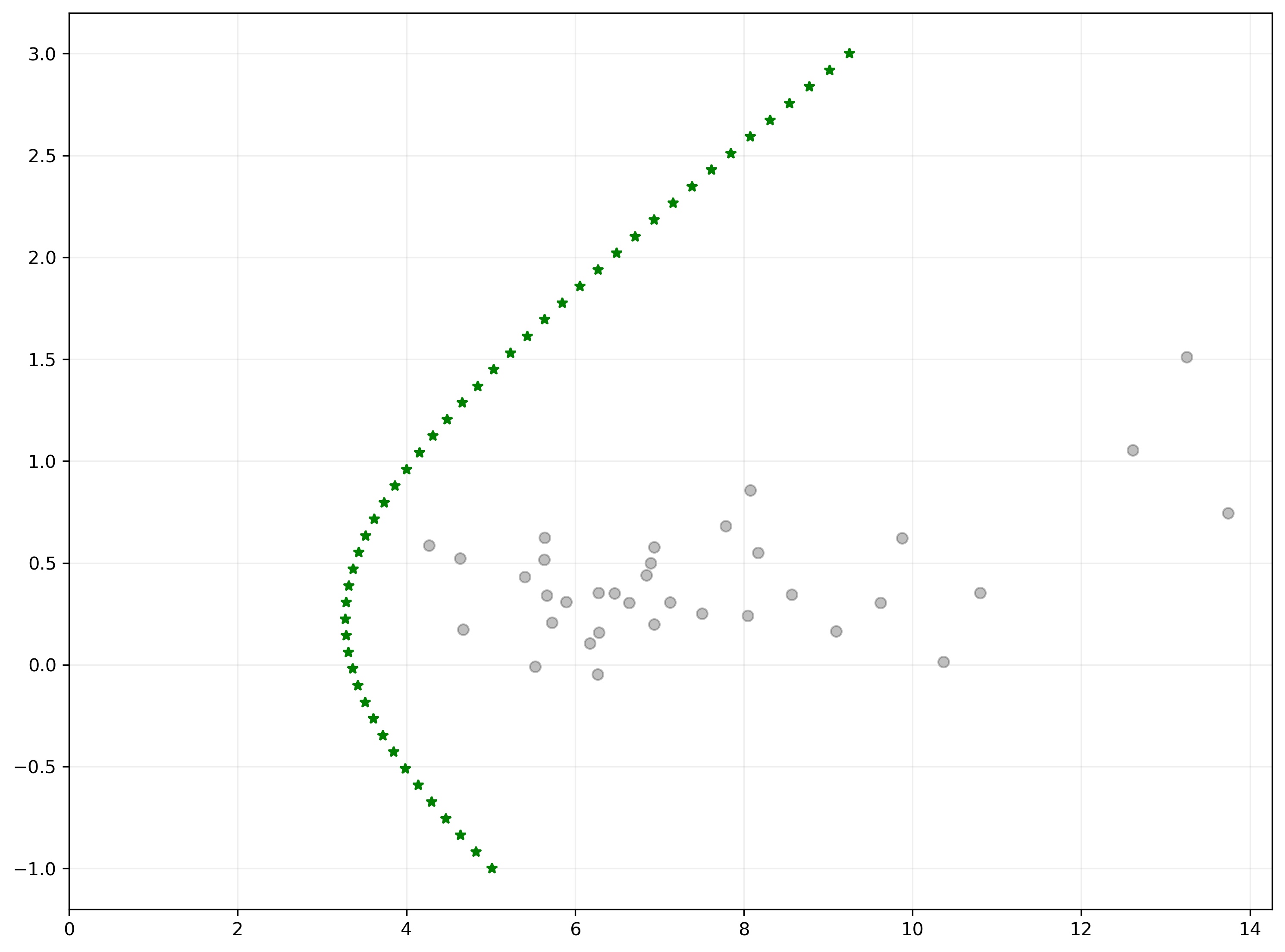
The GMV portfolio#
Analytically, we found the GMV by minimizing the function for the variance of an efficient portfolio. We set the derivative equal to zero, and solved.
Working numerically, we accomplish the same thing by specifying a new problem, although without a constraint to achieve any particular target return. That is, the problem is simply to find the minimum variance of any feasible portfolio, regardless of its expected return.
To implement this, all we have to do is redefine the constraint:
cons_gmv = {'type': 'eq',
'fun': lambda w: np.sum(w) - 1}
gmv = sco.minimize(portvar, ewgts, constraints=cons_gmv, method='SLSQP')
gmv
message: Optimization terminated successfully
success: True
status: 0
fun: 10.73223034813583
x: [-5.970e-03 -5.116e-02 ... 4.191e-01 5.893e-01]
nit: 37
jac: [ 2.146e+01 2.146e+01 ... 2.146e+01 2.146e+01]
nfev: 1392
njev: 37
mvs(gmv['x'])
(0.22031203591864054, 3.2760082948820246, 0.06725014593608482)
The tangency portfolio#
We previously saw that the Tangency portfolio has the maximum possible Sharpe ratio of any portfolio. The problem is therefore
The only complication is that scipy provides a method to minimize a function, but not maximize one. Not to worry: if we simply multiply our function by minus one and find the maximum, we will have found the minimum of the original function. (Maximizing \(f(x) = -x^2\) is the same as minimizing \(f(x) = x^2\). Either way the answer is \(x=0\).)
def neg_sharpe(weights):
return -mvs(weights)[2]
tng = sco.minimize(neg_sharpe, ewgts,
constraints=cons_gmv, # note same constraints as GMV
method='SLSQP')
tng
message: Optimization terminated successfully
success: True
status: 0
fun: -0.32817872582544483
x: [ 3.155e-01 -3.945e-02 ... -2.433e+00 2.785e+00]
nit: 62
jac: [ 1.707e-05 -2.410e-05 ... -2.815e-05 3.124e-05]
nfev: 2233
njev: 62
mvs(tng['x'])
(5.266595120386297, 16.047947980599904, 0.32817872582544483)
The Sharpe ratio of the tangency portfolio is about 4.9 times that of the GMV portfolio.
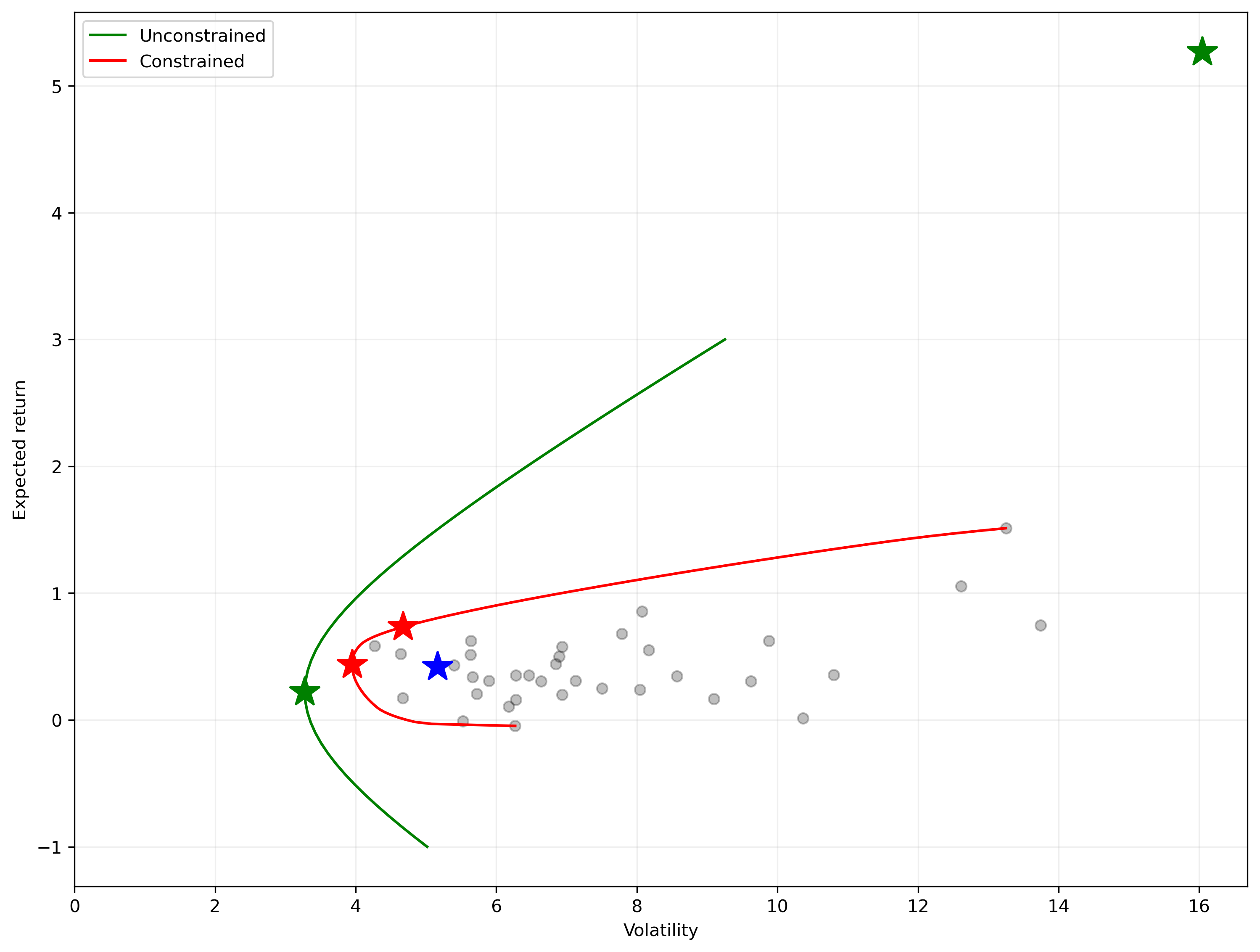
Changing the constraints#
So far, we used the minimization algorithm to get an answer that we already know how to find using analytical methods. So what is the benefit of using a numerical solver?
Numerical solutions can be found for problems that are much harder or even impossible to solve with analytical techniques.
Short-sale constraints#
For example, many investors, including mutual funds, cannot engage in short selling. That is, they cannot hold a negative position in any asset.
We can represent their problem by adding one additional set of constraints to the problem that requires that all values of \(\omega\) must be nonnegative.
This problem is much harder to solve analytically, but trivial for the scipy algorithm. We simply add additional constraints to the problem.
The constraint that \(\omega_i > 0\) is actually a special type of constraint called a boundary. These are easiest to implement by passing a list of upper- and lower-bounds to the algorithm.
bounds = [(0, 1) for w in range(N)]
With a long-only portfolio there is no way to construct a portfolio with a return that is less than that of the lowest-return asset, or above that of the highest-return asset, so we have to choose a target return in that range.
tret = 1.2
assert tret<max(μ), 'Target return is infeasible'
cons = [
# expected return equals target return
{'type': 'eq', 'fun': lambda w: mvs(w)[0] - tret},
# weights sum to one
{'type': 'eq', 'fun': lambda w: np.sum(w) - 1}
]
p2 = sco.minimize(portvar, ewgts, constraints=cons, bounds=bounds, method='SLSQP')
p2['message']
'Optimization terminated successfully'
p2['x']
array([5.38200460e-01, 8.45469096e-12, 0.00000000e+00, 1.18181892e-11,
1.37535691e-01, 3.82095150e-11, 0.00000000e+00, 1.39020579e-01,
0.00000000e+00, 3.77145626e-12, 0.00000000e+00, 0.00000000e+00,
9.83537574e-12, 2.22218161e-02, 0.00000000e+00, 2.73867617e-12,
4.94130278e-11, 0.00000000e+00, 5.57947183e-11, 0.00000000e+00,
1.63021453e-01, 1.97171388e-11, 1.16450455e-11, 0.00000000e+00,
0.00000000e+00, 3.31904530e-12, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 9.05294384e-11, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 3.85066583e-11, 1.23520081e-10])
The portfolio has the desired expected return of 6%, volatility of about 14%, and a Sharpe ratio of 0.43.
mvs(p2['x'])
(1.200000000184108, 9.065564423145695, 0.1323690334294393)
Check your understanding
The Sharpe ratio of this minimum-variance portfolio is significantly less than what we found above when we didn’t impose short-sale constraints. Why?
Many of the weight in the portfolio are now zero:
w = pd.Series(p2['x'], index=rets.columns)
w[w>0.0001].sort_values(ascending=False)
Argentina 0.538200
Mexico 0.163021
Denmark 0.139021
Brazil 0.137536
India 0.022222
dtype: float64
Exercise
Suppose a hedge fund can use leverage (that is, borrow money) to buy stocks. This leverage allows the fund to have 200% of its capital invested in its portfolio. Also, it can short stocks, but only up to a weight of –20% in each stock; similarly it cannot have a weight of more than +50% in any stock. What are the expected return, volatility, and Sharpe ratio of its this fund’s tangency portfoio?
Variations#
There are numerous ways that we might want to constrain the optimization problem:
We might want a sparse solution, where we only select a small number of assets to hold.
Alternatively, we might want to require a certain number of assets in the portfolio, or a minimum holding in every asset.
We could add a cost of shorting.
We could include transaction costs that reflect the cost of adjusting our portfolio from its current holdings. An often-used model if transaction cost is, for a given trade size \(x\),
where \(a\), \(b\), and \(c\) are parameters, \(\sigma\) is volatility, and \(V\) is the volume of trading in the asset. \(a\) reflects the bid–ask spread. See, for example, Boyd et al. (2017).
Utility maximization#
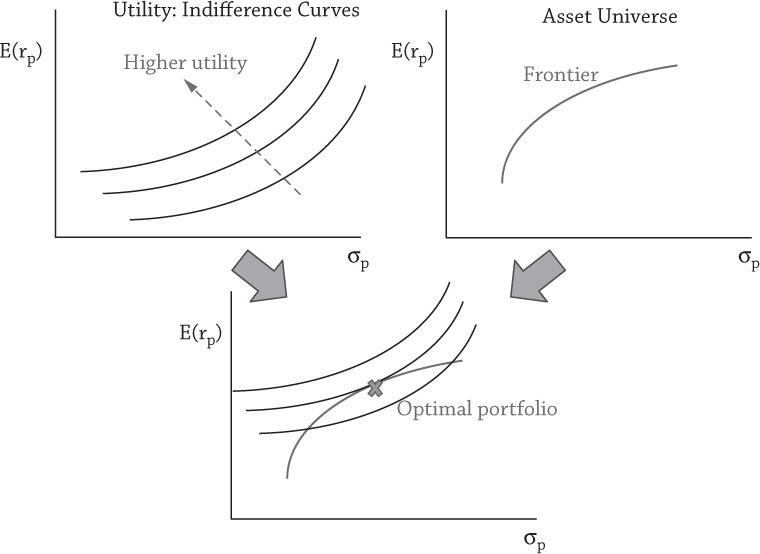
Source: Ang [2014], Figure 3.8.