
Covariance#
Consider the variance of the sum of two random variables,
Clearly, the variance equals the sum of the two variances, plus an additional term involving the product of the two random variables. This term is the covariance, which measures the tendency of two random variables to move together. It’s defined as
Note
In general, \(\E(XY) \neq \E(X)\E(Y),\) since
except in special cases.
Exercise
Show that:
\(\cov(X,Y) = \cov(Y,X)\)
\(\cov(X,X) = \var(X)\)
\(\cov(aX,bY) = ab\cov(X,Y)\)
\(\cov(a+X,b+Y) = \cov(X,Y)\)
Note that facts #2 and #3 imply that \(\var(bX) = b^2\var(X)\), as we saw earlier.
The variance–covariance matrix#
It will often be useful to think about variance and covariance simultaenously for multiple variables, which is easiest to do in a matrix context. Suppose that \(X\) and \(Y\) are random variables, and let \(Z = \begin{pmatrix}X\\Y\end{pmatrix}\). The variance of \(Z\) is
Therefore,
This is the variance–covariance matrix, often denoted \(\boldsymbol{\Sigma}\). It contains information about all the variances and covariances for the cross terms. Since we have two random variables, the matrix is \(2\times 2\).
The variance–covariance matrix can be defined for an arbitrary number of variables. For example, suppose we have \(n\) random variables, \(X_1, X_2, \ldots, X_n.\) The variance–covariance matrix is
where \(\sigma_{ij} := \cov(X_i,X_j).\) The matrix is clearly square, with \(n\) rows and \(n\) columns, as well as symmetric about the diagonal, since \(\sigma_{ij} = \sigma_{ji}\).
Correlation#
Correlation is a scaled measure of covariance calculated as
An important result in math, called the Cauchy–Schwarz inequality, says that
implying that
Correlation must therefore lie in the interval \([-1,1]\).
We use the following terms to describe how \(X\) and \(Y\) are related, given their correlation.
\(\rho_{X,Y}\) |
Meaning |
|---|---|
\(\rho = -1\) |
Perfectly negatively correlated |
\(\rho < 0\) |
Negatively correlated |
\(\rho = 0\) |
Uncorrelated |
\(\rho > 0\) |
Positively correlated |
\(\rho = 1\) |
Perfectly positively correlated |
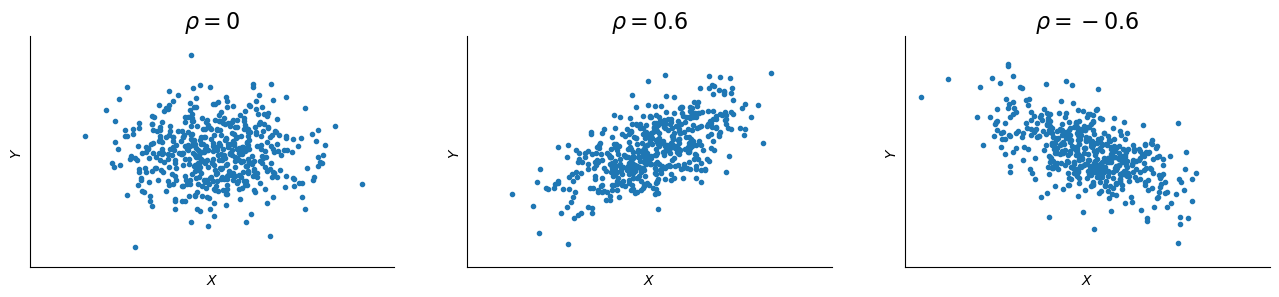
The figure below shows the correlation of three simulated datasets. In each panel, we take 500 random draws for two variables \(X\) and \(Y\) that are each normally distributed but have a correlation of \(\rho\). Each \((x_i, y_i)\) pair is plotted. In the left panel, the data are uncorrelated and there is no obvious pattern between the the values of \(x_i\) and \(y_i\). Both values tend to be near zero, but when one value is high or low, it doesn’t tell us anything about whether the other value is high or low.
In the second panel, with correlation of 0.6, there is a clear positive relation: when \(x_i\) is high, \(y_i\) also tends to be high; and when \(x_i\)is low, \(y_i\) tends also to be low. In the third panel, the pattern is flipped, so high values of \(x_i\) are generally paired with low values of \(y_i\), and vice versa.
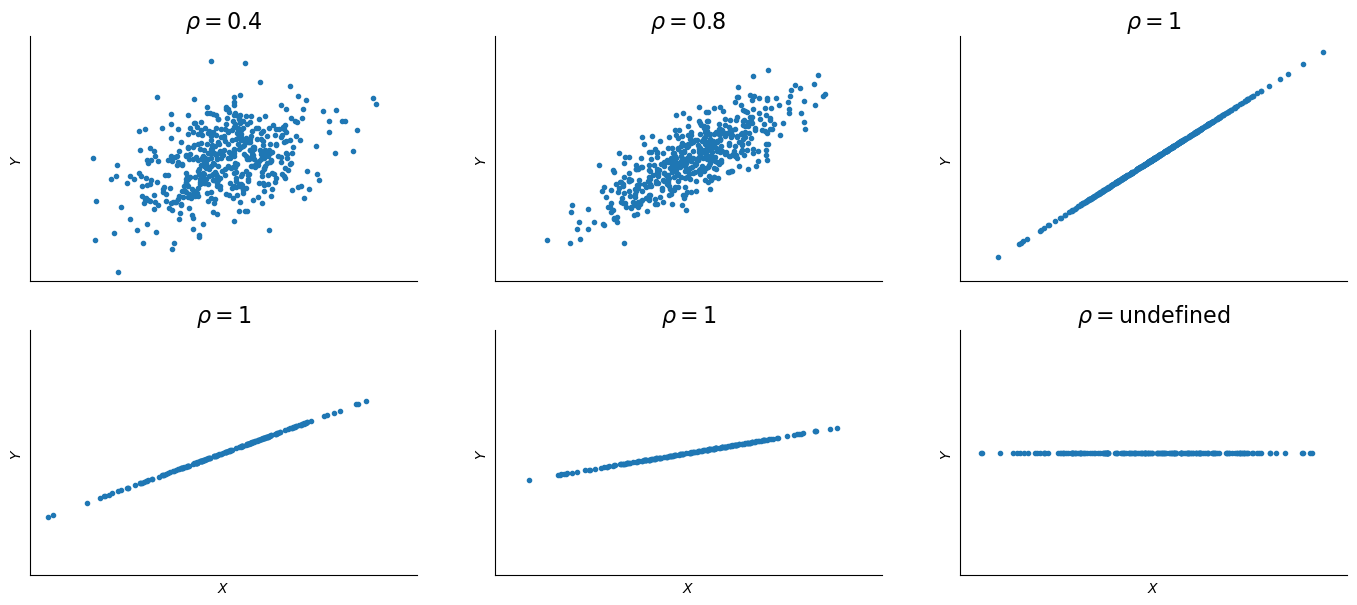
As we increase correlation, the connection between the two random variables becomes tighter, as can be seen in the plots below. When variables are perfectly correlated, they move exactly together, so the data line up on a straight line. The slope of the line need not be 45°. In the lower right panel, \(Y\) does not vary, so \(\sigma_Y=0\) and correlation cannot be calculated (although covariance is zero).
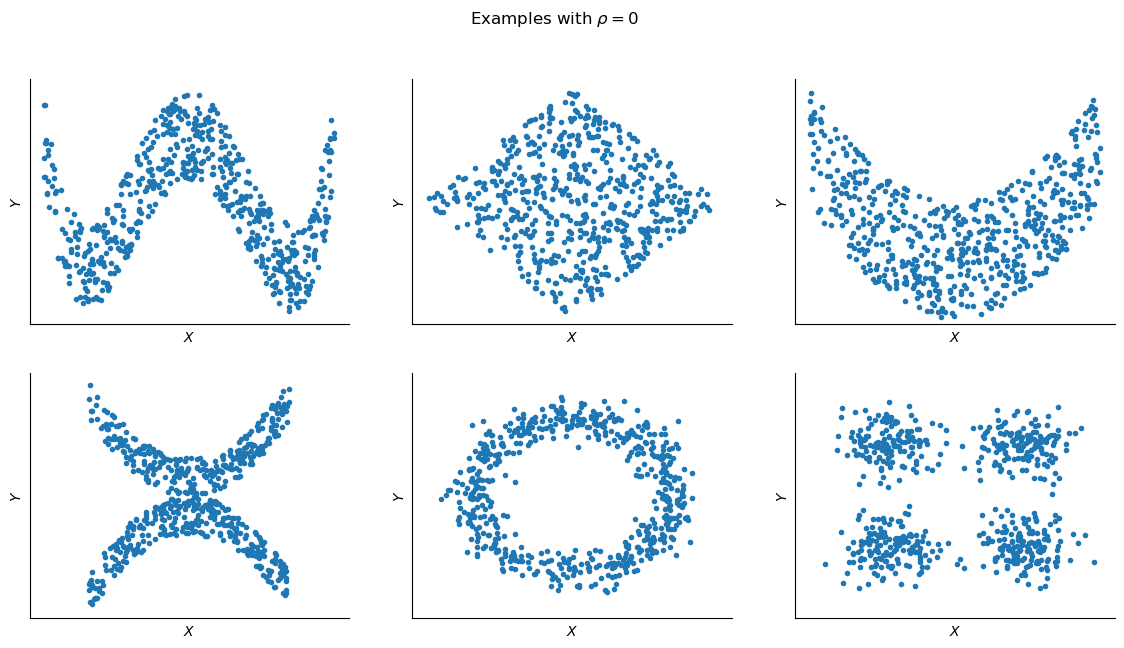
If the variables are independent, the correlation coefficient is 0, but the converse is not true because the correlation coefficient detects only linear dependencies between two variables. This is depicted in the figure below, which provides six examples of data where there is clearly some relation between \(X\) and \(Y\) despite all having a correlation of zero. In all of these cases, the dependence between the variables is nonlinear, and correlation cannot detect such patterns.
Formally, the relation between independence and correlation is
Note, however, that if either \(X\) or \(Y\) are constant (``non-stochastic’’) then their correlation will be undefined even though they are independent.
Key fact
Correlation can range from \(-1\) to \(1\). It is zero whenever \(X\) and \(Y\) are independent random variables, although it can also be zero even if they are not independent.