
Diversification#
import numpy as np
rng = np.random.default_rng(8675309)
import matplotlib.pyplot as plt
import seaborn as sns
Suppose we have two assets, \(i=\{1,2\}\), each with a return of \(R_i\). We hold them in a portfolio with weights \(\omega\) and \(1-\omega\), respectively. The return on the portfolio is then
Applying the equations for expected value, we find that the expected return on the portfolio is
Similarly, the variance is
The first term is
Similarly, the second term is
Putting them together, we have
More generally, if we have \(N\) assets with weights \(\omega_i\), the variance is
In vector notation, this is simply
where \(\boldsymbol{\omega} = (w_1, \cdots, w_N)'\) is the vector of weights, and \(\boldsymbol{\Sigma}\) is the variance–covariance matrix.
Exercise
For the \(N=3\) case, verify that \(\boldsymbol{\omega}' \boldsymbol{\Sigma} \boldsymbol{\omega}\) is the same as \(\sum_{i=1}^N \omega_i^2 \sigma_i^2 + \sum_{i,j} \omega_i \omega_j \sigma_{ij}\).
Solution
The algebra is a little tedious, but straightforward:
Note that we’re simplifying the answer using the fact that \(\sigma_{ij} = \sigma_{ji}\).
Consider the case an equal-weighted portfolio, where each weight is \(1/N\). The variance is then
As \(N\) gets large, the first term approaches zero and the second term approaches the average of all the covariance terms. The same sort of thing happens in large portfolios even if they are not equally-weighted because each weight term will tend to be small.
Key fact
When assets are held in a diversified portfolio, the variances of individual assets do not contribute meaningfully to the portfolio’s variance. All that matters is the covariances of the assets.
The figure below plots the volatility of all possible portfolios combining two assets with \(\mu_1 = 0.1\), \(\mu_2 = 0.2\), \(\sigma_1=0.2\), \(\sigma_2=0.3\), and \(\rho = 0.2\). For some values of \(\omega\), the portoflio’s volatility is less than the volatility of either of the two assets; this is the benefit of diversification.
# Expected return vector
μ = np.array([0.1, 0.2])
# Volatilities and correlation
σ1 = 0.2
σ2 = 0.3
ρ = 0.2
# Calculate Σ matrix
σ12 = ρ * σ1 * σ2
Σ = np.array([[σ1**2, σ12],
[σ12, σ2**2]])
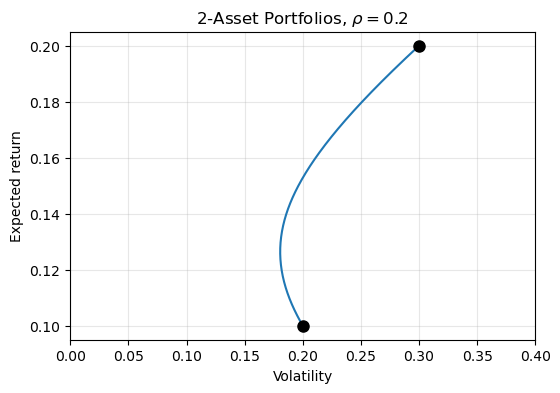
As we vary the correlation, the extent to which diversifcation affects the portfolio’s volatility changes.
Select a value for the correlation:
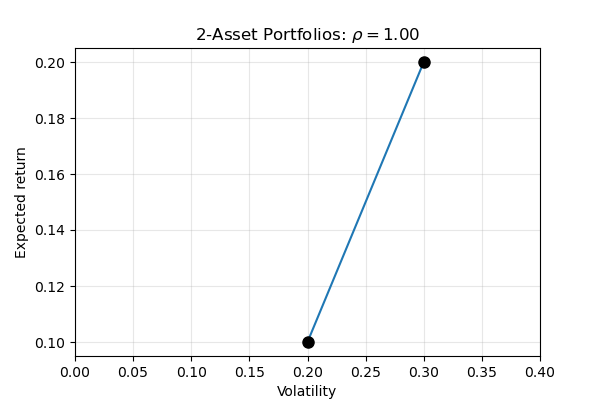
Notice that when the two assets are perfectly correlated there are no benefits to diversification: all feasible portfolios are on the straight line between the two assets, so as expected return increases, so does the volatility.
And when the two assets are perfectly negatively correlated, we can actually get rid of all the volatility in the portfolio.
In this example, it looks like this “riskfree” portfolio has a return of 14%. Where does this come from? How do we know how much weight to put in each asset to achieve the riskfree return? We can find this by beginning with the portfolio variance:
What is the minimum possible variance we can achieve? To answer this, we need to choose a weight \(\omega\) that minmizes the variance. We know how to minimize a function: just take the derivative and set it equal to zero.
The derivative is
Setting this equal to zero and solving, we find that variance is minimized when the weight in the first asset is
and the weight in the second asset is
For the particular example in the figure, we have
The weight is therefore
That is, the riskfree portfolio has weights of 60% in the first asset and 40% in the second. The return on this portfolio is
as we expected from the graph.
Finally, we can verify that this portfolio has a variance of zero:
Three assets#
Let’s look at what diversification looks like with three assets.
def gen_er_sigma(n):
'''Generate a (random) expected return vector and
a variance-covariance matrix for n assets
'''
μ = np.abs(rng.standard_normal((n, 1))) / 10
tmp = rng.standard_normal((n, n)) / 10
Σ = tmp.T @ tmp
return μ, Σ
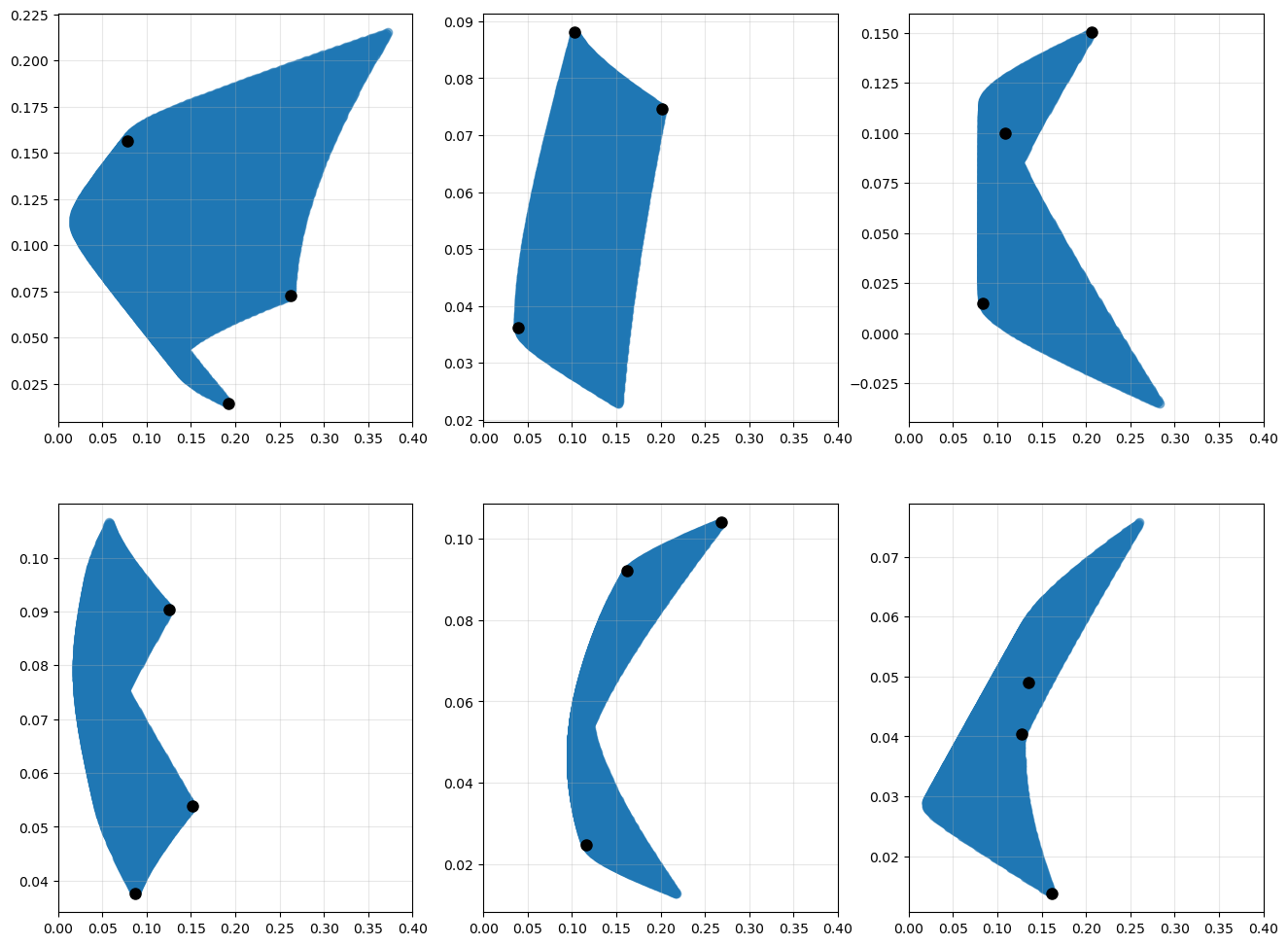
More assets#
As we add more assets, it becomes much more computationally demanding to look at all possible combinations of weights. Instead, we can form portfolios randomly to see what sort of diversification benefits we see.
def random_ports(μ, Σ, nports=100):
'''Generate random portfolios given an expected return
vector and covariance matrix
'''
n = μ.shape[0]
prets = []; pvols = []
for i in range(nports):
w = rng.uniform(size=n)
w /= w.sum()
prets.append(float(w @ μ))
pvols.append(np.sqrt(w @ Σ @ w))
prets = np.array(prets)
pvols = np.array(pvols)
return(prets,pvols)
# generate expected return and covariance
μ, Σ = gen_er_sigma(10)
# generate random portfolios
prets, pvols = random_ports(μ, Σ, nports=100)
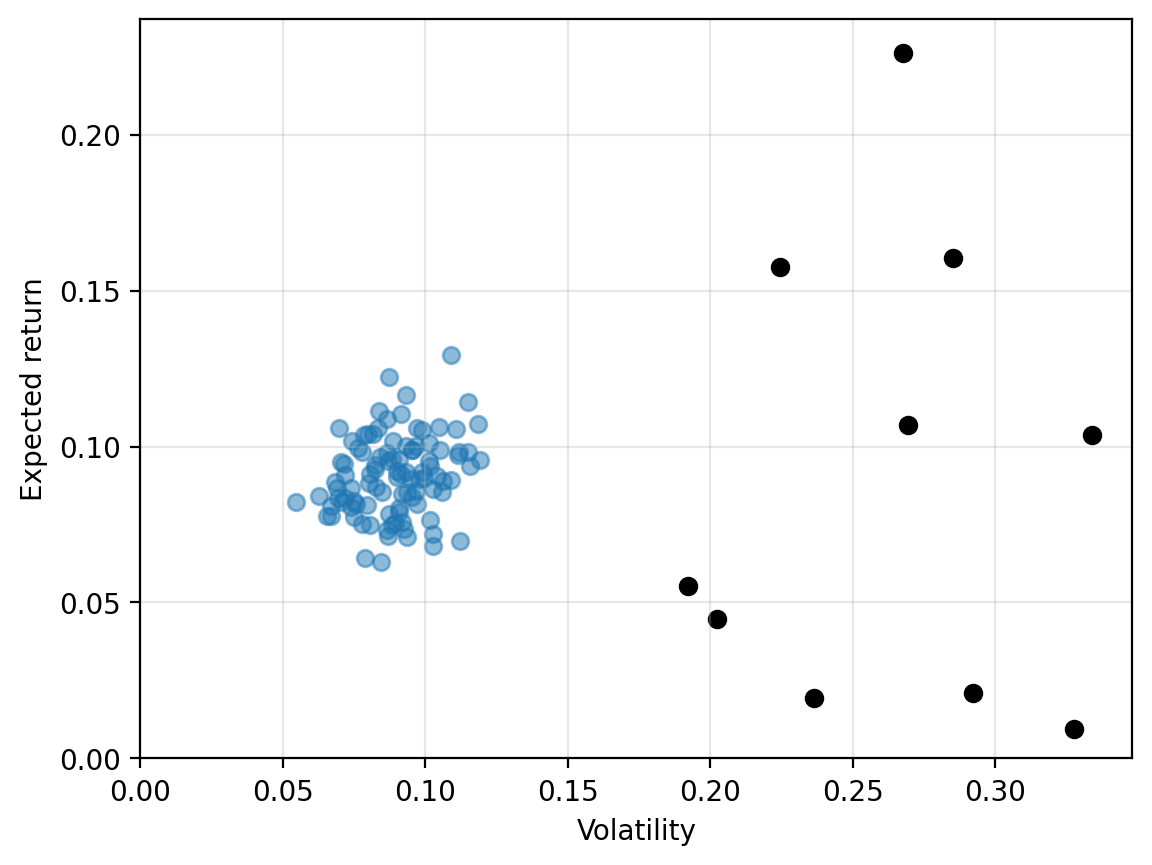
What else do investors care about?#
When we plot assets in volatility–return space, we are implicitly assuming that these are the only things investors care about. Certainly that is not right. Investors may not want to buy shares of a company that pollutes the environment, sells weapons to oppressive regimes, or uses suppliers that rely on child labor. In fact, Hong and Kacperczyk [2009] find that so-called “sin” stocks, including firms that produce tabacco, and alcohol, and gaming, have historically earned higher returns, perhaps due to some investors’ unwillingness to buy these companies. (More recently, Blitz and Fabozzi [2017] dispute this evidence.)
Investors may also care about statistical features of stocks other than simply the expected return and volatility. Other moments, such as skewness and kurtosis, may be important. Indeed, Kumar [2009] finds that individual investors prefer stocks with “lottery-like” features such as a low probability of a high return.