
Linear regression#
Suppose we have 100 observations of pairs of data, an outcome \(y_i\) and an explanatory variable \(x_i\). The figure below shows an example of such data.
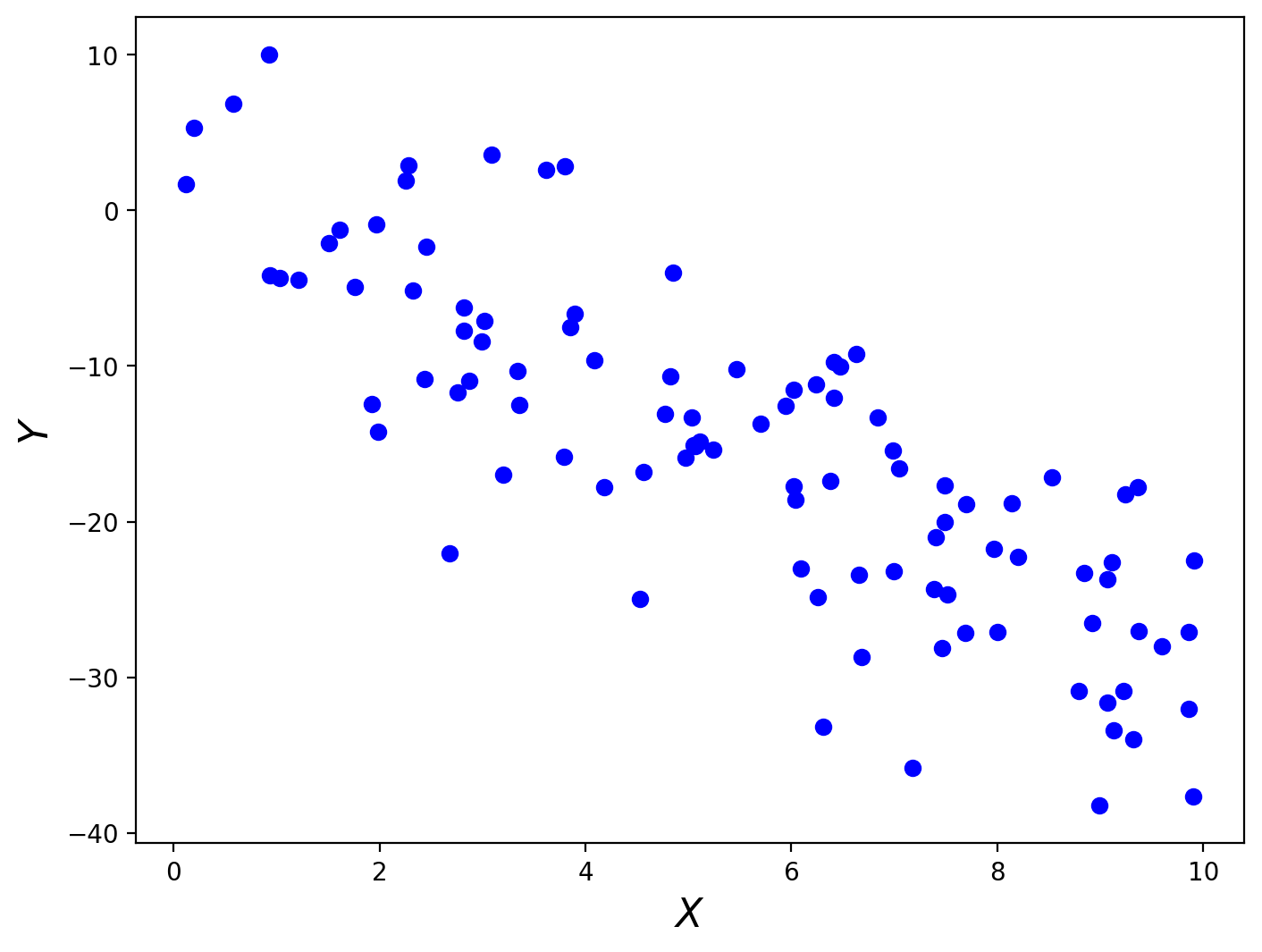
Our objective is to understand the relation between \(X\) and \(Y\). This might be because we’re intrinsically interested in how these variables are related, or more generally we may be interested simply in predicting what \(y_i\) would be for some new value of \(x_i\) that isn’t in our data.
One model for how the data might be related is the linear model
where \(\beta_0\) is the intercept or constant, \(\beta_1\) is the slope coefficient, and the error or noise term \(\varepsilon\) is assumed to follow
That is, each \(\varepsilon_i\) is independently and identically (iid) normally distributed with mean zero and variance \(\sigma^2\). The coefficients or parameters \(\beta_0\), \(\beta_1\), and \(\sigma^2\) must be estimated from the data.
The model can be written more compactly using vector notation as
where
The design matrix, \(X\), is a \(N\times (K+1)\) matrix, where we have \(K\) explanatory variables. In this simple case, \(K=1\). (We add one column to the design matrix to account for the intercept term in the regression.)
# construct the X matrix
X = np.c_[np.ones(N), x]
X
array([[1. , 3.78932572],
[1. , 8.14510763],
[1. , 6.25815208],
[1. , 9.06732906],
[1. , 1.51201567],
[1. , 3.35945273],
[1. , 4.77343805],
[1. , 5.02944731],
[1. , 3.20385337],
[1. , 6.98991629],
[1. , 0.93549912],
[1. , 9.60145739],
[1. , 2.82288409],
[1. , 6.23623746],
[1. , 9.22986082],
[1. , 9.36331049],
[1. , 0.19613871],
[1. , 2.45358141],
[1. , 4.85431758],
[1. , 9.11233189],
[1. , 3.09033301],
[1. , 5.70593544],
[1. , 8.0015214 ],
[1. , 6.9984128 ],
[1. , 5.10762591],
[1. , 3.33947923],
[1. , 2.32362688],
[1. , 7.40113077],
[1. , 9.90912306],
[1. , 7.46814805],
[1. , 9.85866987],
[1. , 5.07204594],
[1. , 9.37496851],
[1. , 7.04934381],
[1. , 0.12397061],
[1. , 8.99037205],
[1. , 3.80096974],
[1. , 6.41390961],
[1. , 4.18691253],
[1. , 7.69913645],
[1. , 8.79152345],
[1. , 6.37914799],
[1. , 6.68576394],
[1. , 2.28496784],
[1. , 6.0957999 ],
[1. , 6.04318223],
[1. , 5.05412458],
[1. , 9.07223282],
[1. , 6.41279701],
[1. , 3.85683938],
[1. , 7.38562053],
[1. , 0.92488618],
[1. , 2.87034247],
[1. , 5.94616768],
[1. , 1.96636734],
[1. , 6.83881273],
[1. , 9.24086347],
[1. , 9.32008681],
[1. , 9.85890061],
[1. , 7.49033628],
[1. , 2.68154467],
[1. , 5.46868578],
[1. , 7.48908539],
[1. , 1.02980244],
[1. , 6.47672066],
[1. , 4.53147238],
[1. , 8.84635465],
[1. , 2.2570779 ],
[1. , 1.99017837],
[1. , 1.75745678],
[1. , 8.53294995],
[1. , 0.57853728],
[1. , 7.51816065],
[1. , 6.02103699],
[1. , 2.8158828 ],
[1. , 3.89821668],
[1. , 1.92948469],
[1. , 4.08890653],
[1. , 6.63104342],
[1. , 8.92565301],
[1. , 2.76036701],
[1. , 8.20130563],
[1. , 2.99066128],
[1. , 5.24300051],
[1. , 7.68925061],
[1. , 7.1778335 ],
[1. , 1.21729107],
[1. , 6.02433167],
[1. , 9.12670588],
[1. , 3.01652468],
[1. , 6.31300866],
[1. , 6.65746208],
[1. , 9.90520943],
[1. , 4.97624774],
[1. , 7.96788852],
[1. , 4.82646891],
[1. , 1.61224955],
[1. , 4.56262183],
[1. , 3.62059203],
[1. , 2.4346172 ]])
Given a particular estimate of \(\beta\), which we denote \(\hat{\beta}\), we predict values for \(Y\) using
It looks from the plot that there’s a clear negative relation between \(X\) and \(Y\) for these data, so let’s guess that \(\beta = \begin{pmatrix} 0\\ -1.5 \end{pmatrix}\).
β_hat = np.array([[0], [-1.5]])
y_hat = X @ β_hat
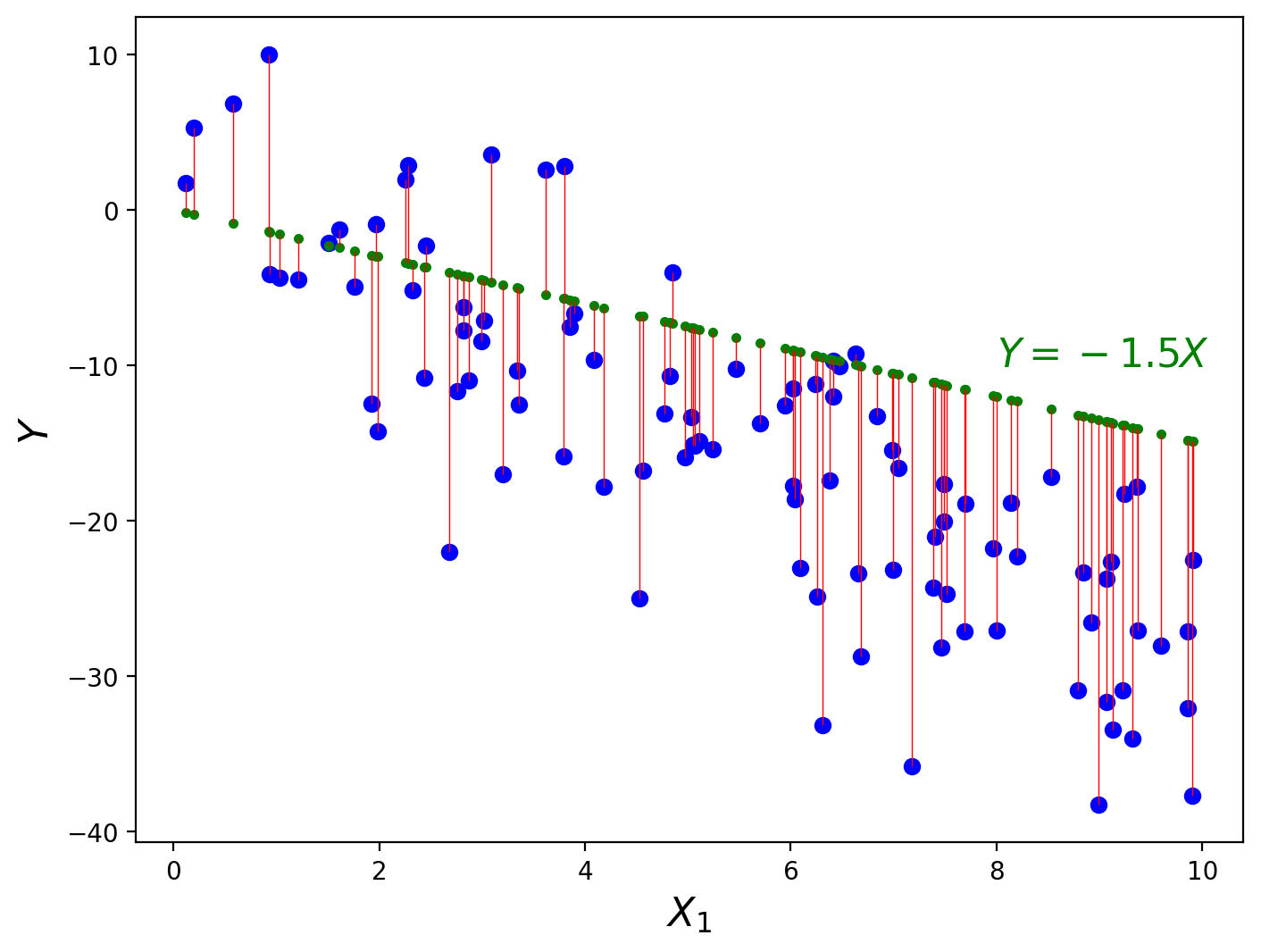
This model doesn’t look like it’s doing a great job of fitting the data. It seems like it’s not quite steep enough. Rather than merely guessing coefficients, though, let’s find a more systematic approach to estimating coefficients.
We want to choose parameters that are in some sense “good”. One way to do this is choose parameters that make the prediction error,
as small as possible. The magnitude of these errors is shown in the figure with the red lines.
ε_hat = y - y_hat
Using our current (not very good) guess of the value of \(\beta\), these are:
| x | y | y_hat | ε_hat | |
|---|---|---|---|---|
| 1 | 3.79 | -15.84 | -5.68 | -10.16 |
| 2 | 8.15 | -18.84 | -12.22 | -6.63 |
| 3 | 6.26 | -24.85 | -9.39 | -15.46 |
| 4 | 9.07 | -31.66 | -13.60 | -18.06 |
| 5 | 1.51 | -2.12 | -2.27 | 0.15 |
| 6 | 3.36 | -12.51 | -5.04 | -7.47 |
| 7 | 4.77 | -13.10 | -7.16 | -5.94 |
| 8 | 5.03 | -13.29 | -7.54 | -5.74 |
| 9 | 3.20 | -16.98 | -4.81 | -12.17 |
| 10 | 6.99 | -15.46 | -10.48 | -4.97 |
| 11 | 0.94 | -4.14 | -1.40 | -2.74 |
| 12 | 9.60 | -28.01 | -14.40 | -13.61 |
| 13 | 2.82 | -6.26 | -4.23 | -2.02 |
| 14 | 6.24 | -11.21 | -9.35 | -1.85 |
| 15 | 9.23 | -30.89 | -13.84 | -17.04 |
| 16 | 9.36 | -17.78 | -14.04 | -3.74 |
| 17 | 0.20 | 5.30 | -0.29 | 5.59 |
| 18 | 2.45 | -2.31 | -3.68 | 1.38 |
| 19 | 4.85 | -4.01 | -7.28 | 3.27 |
| 20 | 9.11 | -22.64 | -13.67 | -8.97 |
| 21 | 3.09 | 3.58 | -4.64 | 8.21 |
| 22 | 5.71 | -13.71 | -8.56 | -5.16 |
| 23 | 8.00 | -27.08 | -12.00 | -15.08 |
| 24 | 7.00 | -23.16 | -10.50 | -12.66 |
| 25 | 5.11 | -14.85 | -7.66 | -7.19 |
| 26 | 3.34 | -10.32 | -5.01 | -5.31 |
| 27 | 2.32 | -5.15 | -3.49 | -1.67 |
| 28 | 7.40 | -20.99 | -11.10 | -9.89 |
| 29 | 9.91 | -22.51 | -14.86 | -7.64 |
| 30 | 7.47 | -28.14 | -11.20 | -16.94 |
| 31 | 9.86 | -27.10 | -14.79 | -12.31 |
| 32 | 5.07 | -15.13 | -7.61 | -7.52 |
| 33 | 9.37 | -27.03 | -14.06 | -12.97 |
| 34 | 7.05 | -16.60 | -10.57 | -6.02 |
| 35 | 0.12 | 1.72 | -0.19 | 1.90 |
| 36 | 8.99 | -38.27 | -13.49 | -24.78 |
| 37 | 3.80 | 2.83 | -5.70 | 8.53 |
| 38 | 6.41 | -9.72 | -9.62 | -0.10 |
| 39 | 4.19 | -17.80 | -6.28 | -11.52 |
| 40 | 7.70 | -18.90 | -11.55 | -7.35 |
| 41 | 8.79 | -30.88 | -13.19 | -17.69 |
| 42 | 6.38 | -17.38 | -9.57 | -7.81 |
| 43 | 6.69 | -28.70 | -10.03 | -18.67 |
| 44 | 2.28 | 2.92 | -3.43 | 6.34 |
| 45 | 6.10 | -23.01 | -9.14 | -13.87 |
| 46 | 6.04 | -18.59 | -9.06 | -9.53 |
| 47 | 5.05 | -15.10 | -7.58 | -7.52 |
| 48 | 9.07 | -23.71 | -13.61 | -10.11 |
| 49 | 6.41 | -12.02 | -9.62 | -2.40 |
| 50 | 3.86 | -7.53 | -5.79 | -1.74 |
| 51 | 7.39 | -24.31 | -11.08 | -13.24 |
| 52 | 0.92 | 10.00 | -1.39 | 11.39 |
| 53 | 2.87 | -10.95 | -4.31 | -6.64 |
| 54 | 5.95 | -12.59 | -8.92 | -3.67 |
| 55 | 1.97 | -0.91 | -2.95 | 2.04 |
| 56 | 6.84 | -13.28 | -10.26 | -3.02 |
| 57 | 9.24 | -18.24 | -13.86 | -4.38 |
| 58 | 9.32 | -33.99 | -13.98 | -20.01 |
| 59 | 9.86 | -32.05 | -14.79 | -17.26 |
| 60 | 7.49 | -20.04 | -11.24 | -8.80 |
| 61 | 2.68 | -22.02 | -4.02 | -17.99 |
| 62 | 5.47 | -10.22 | -8.20 | -2.02 |
| 63 | 7.49 | -17.65 | -11.23 | -6.42 |
| 64 | 1.03 | -4.33 | -1.54 | -2.78 |
| 65 | 6.48 | -10.02 | -9.72 | -0.30 |
| 66 | 4.53 | -24.96 | -6.80 | -18.16 |
| 67 | 8.85 | -23.31 | -13.27 | -10.04 |
| 68 | 2.26 | 1.95 | -3.39 | 5.34 |
| 69 | 1.99 | -14.21 | -2.99 | -11.23 |
| 70 | 1.76 | -4.91 | -2.64 | -2.27 |
| 71 | 8.53 | -17.18 | -12.80 | -4.38 |
| 72 | 0.58 | 6.88 | -0.87 | 7.74 |
| 73 | 7.52 | -24.68 | -11.28 | -13.40 |
| 74 | 6.02 | -17.73 | -9.03 | -8.70 |
| 75 | 2.82 | -7.72 | -4.22 | -3.49 |
| 76 | 3.90 | -6.64 | -5.85 | -0.80 |
| 77 | 1.93 | -12.43 | -2.89 | -9.54 |
| 78 | 4.09 | -9.63 | -6.13 | -3.50 |
| 79 | 6.63 | -9.21 | -9.95 | 0.73 |
| 80 | 8.93 | -26.55 | -13.39 | -13.16 |
| 81 | 2.76 | -11.67 | -4.14 | -7.53 |
| 82 | 8.20 | -22.28 | -12.30 | -9.97 |
| 83 | 2.99 | -8.44 | -4.49 | -3.95 |
| 84 | 5.24 | -15.40 | -7.86 | -7.54 |
| 85 | 7.69 | -27.13 | -11.53 | -15.60 |
| 86 | 7.18 | -35.81 | -10.77 | -25.04 |
| 87 | 1.22 | -4.46 | -1.83 | -2.63 |
| 88 | 6.02 | -11.50 | -9.04 | -2.46 |
| 89 | 9.13 | -33.42 | -13.69 | -19.73 |
| 90 | 3.02 | -7.12 | -4.52 | -2.59 |
| 91 | 6.31 | -33.16 | -9.47 | -23.70 |
| 92 | 6.66 | -23.40 | -9.99 | -13.41 |
| 93 | 9.91 | -37.69 | -14.86 | -22.83 |
| 94 | 4.98 | -15.90 | -7.46 | -8.44 |
| 95 | 7.97 | -21.75 | -11.95 | -9.79 |
| 96 | 4.83 | -10.69 | -7.24 | -3.45 |
| 97 | 1.61 | -1.26 | -2.42 | 1.16 |
| 98 | 4.56 | -16.79 | -6.84 | -9.94 |
| 99 | 3.62 | 2.60 | -5.43 | 8.03 |
| 100 | 2.43 | -10.81 | -3.65 | -7.15 |
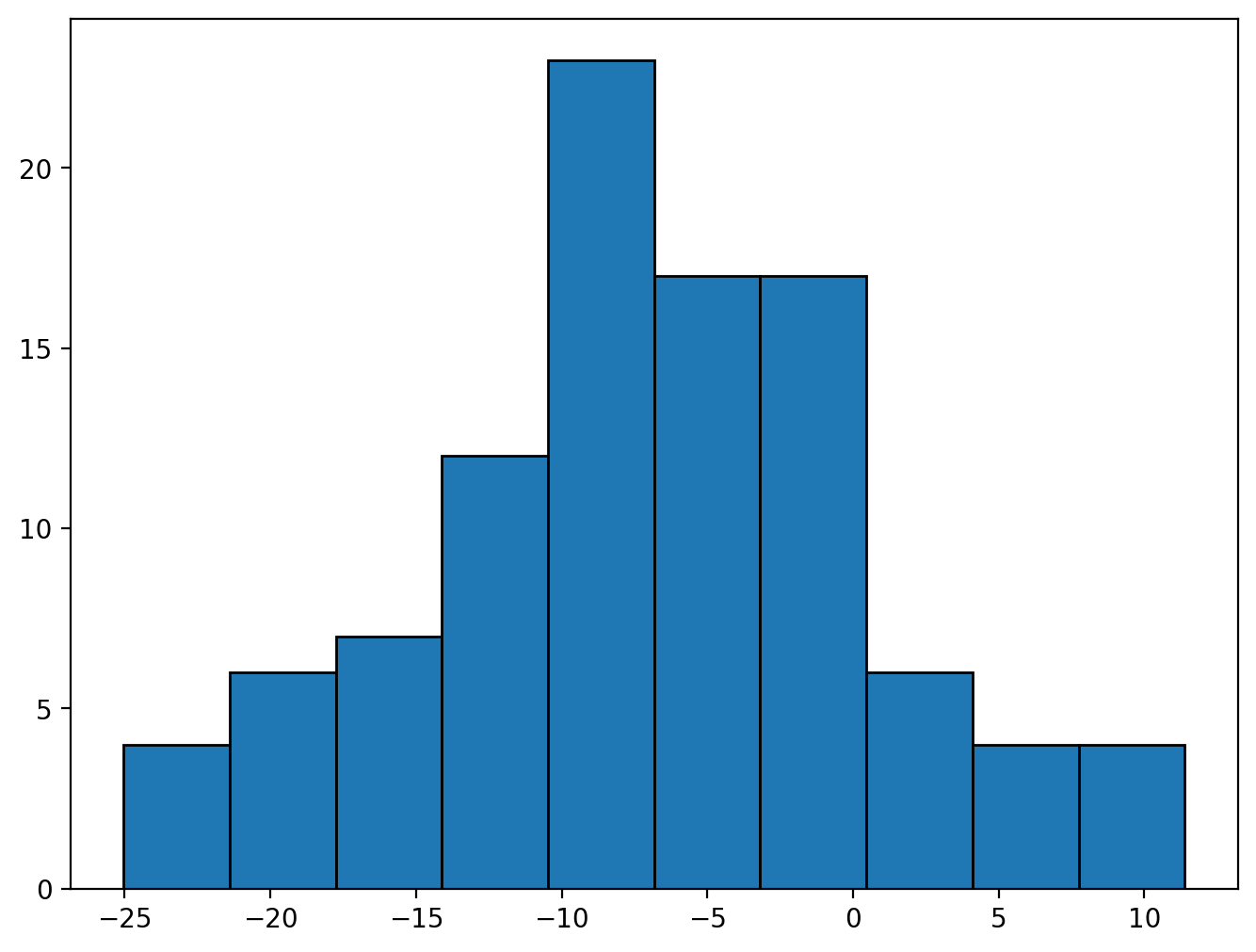
Looking at the histogram for all 100 error terms, we see that the average error is about –3, and some errors are quite large in absolute terms. If we’re more strategic about choosing a better estimate of \(\hat\beta\) we should be able to make these errors smaller.
To minimize the errors, it is helpful to summarize the errors is with the Mean Squared Error,
(ε_hat**2).mean()
np.float64(110.76764360488218)
In vector notation, this is just
ε_hat.T @ ε_hat / N
array([[110.7676436]])
The MSE is a function of the \(\hat\beta\) estimates: as we change our guess for the true values of \(\beta\), we generate a new set of error terms, and therefore a new mean squared error.
def MSE(β_hat):
β_hat = np.array(β_hat).reshape(2,1)
ε = y - X @ β_hat
return (ε.T @ ε).item() / N
Given this function, we can try some different values for \(\hat \beta\).
MSE(β_hat)
110.76764360488218
MSE([1, -1.5])
126.15092703695537
MSE([2, -2])
89.6405313433802
We want to find the values of \(\hat\beta_0\) and \(\beta_1\) that minimize this function. First, let’s set \(\hat{\beta}_0=0\) and see how MSE varies as \(\hat\beta_1\) changes.
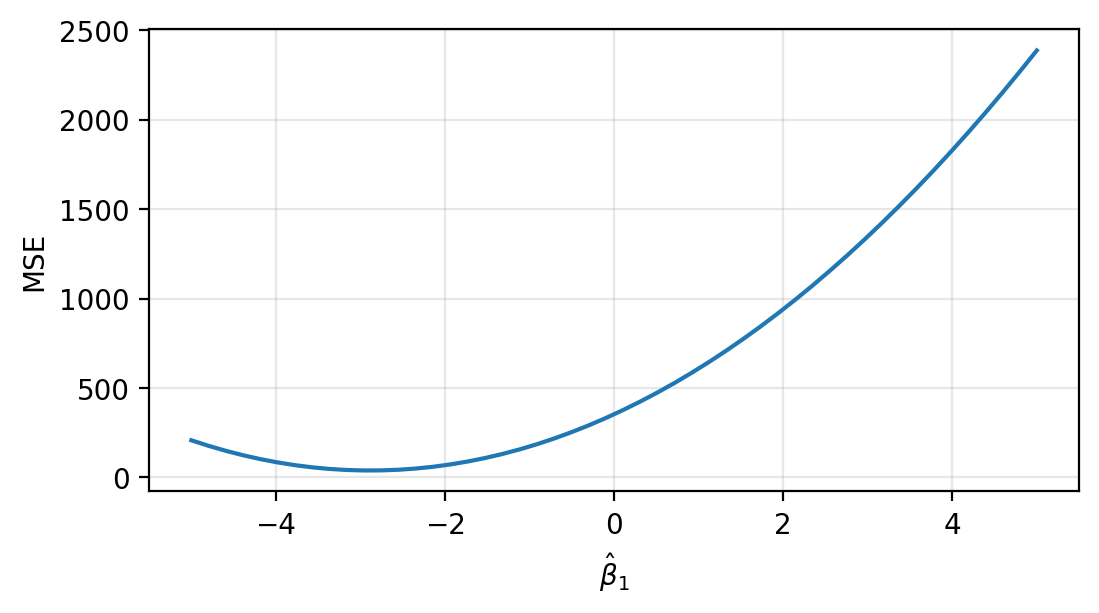
It looks like the MSE is minimized near \(\hat\beta_1=-3\). Let’s hold that value fixed and see how MSE varies as we change \(\hat\beta_0\).
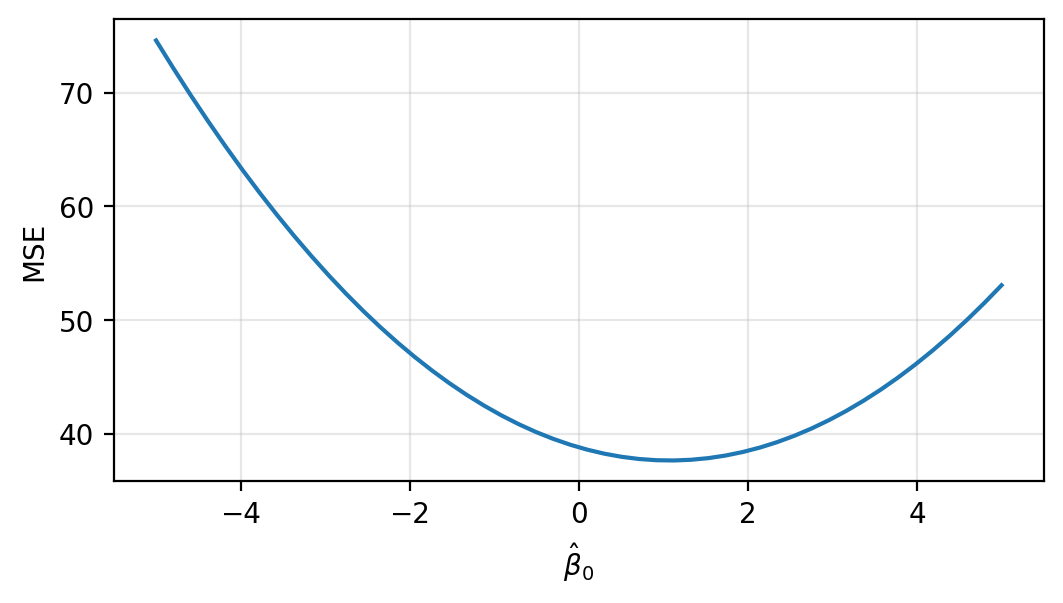
It looks like a value a little less that \(\beta_0=2\) is best. We can do better by varying both \(\beta_0\) and \(\beta_1\) simultaneously.
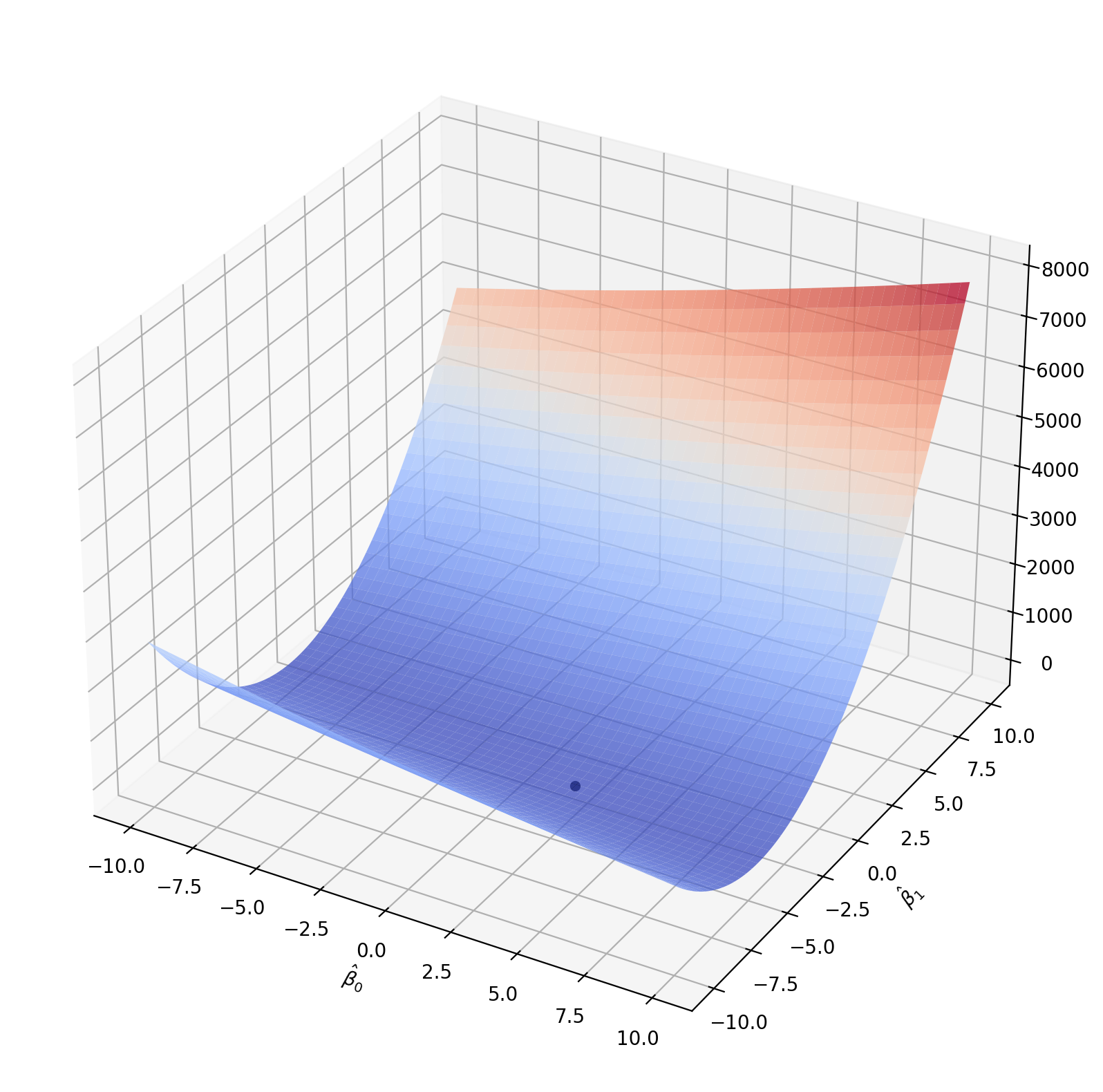
The point on this grid with the lowest MSE, marked in black, is (np.float64(2.45), np.float64(-3.25)), which yields an MSE of np.float64(37.34).
We did manage to find a pretty good estimate, but note that this is really not a good way to find parameters. We had to check blindly if possible parameter values worked well. What if we didn’t start looking anywhere near the correct values? Specifically, what if \(\beta_0=-523\) and \(\beta_1=4367\)? Or what if we have ten explanatory variables rather than just one? We might have to search through trillions of combinations before finding a good fit. Surely there’s a better way to estimate the coefficients!
Gradient descent#
Looking at the MSE function in the figure above, we can see that it is bowl-shaped. (This particular bowl is much steeper in the \(\beta_1\) axis than in the \(\beta_0\) axis.) This is because the MSE is a sum of squares, so it is a convex function. Convex functions are especially easy to minimize using a simple algorithm that uses a little knowledge of calculus to iteratively search in the right direction. In each iteration of the algorithm, we use the derivatives to decide how to improve on our previous guess.
With two parameters, \(\beta_0\) and \(\beta_1\), the MSE function is
The partial derivatives are therefore
and
In vector notation, this is
This vector is called the gradient of the function.
Gradient descent works as follows:
Initialize the \(\hat\beta\) parameters. This can just be a random guess.
Calculate the gradient, \(\Delta := \frac{\partial MSE}{\partial \hat\beta}\).
Update the coefficient estimate according to
Steps 2 and 3 are repeated until the process converges, meaning that \(\hat\beta\) is no longer changing. (Recall that at the minimum of a function, the derivative is zero, so \(\Delta\) will just be a vector of zeros.
The parameter \(\eta\) is called the learning rate and controls how large of a step we take in the direction of the gradient.
β = rng.standard_normal((2,1)) # random initialization
y_hat = X @ β
gradient = -2/N * X.T @ (y - y_hat)
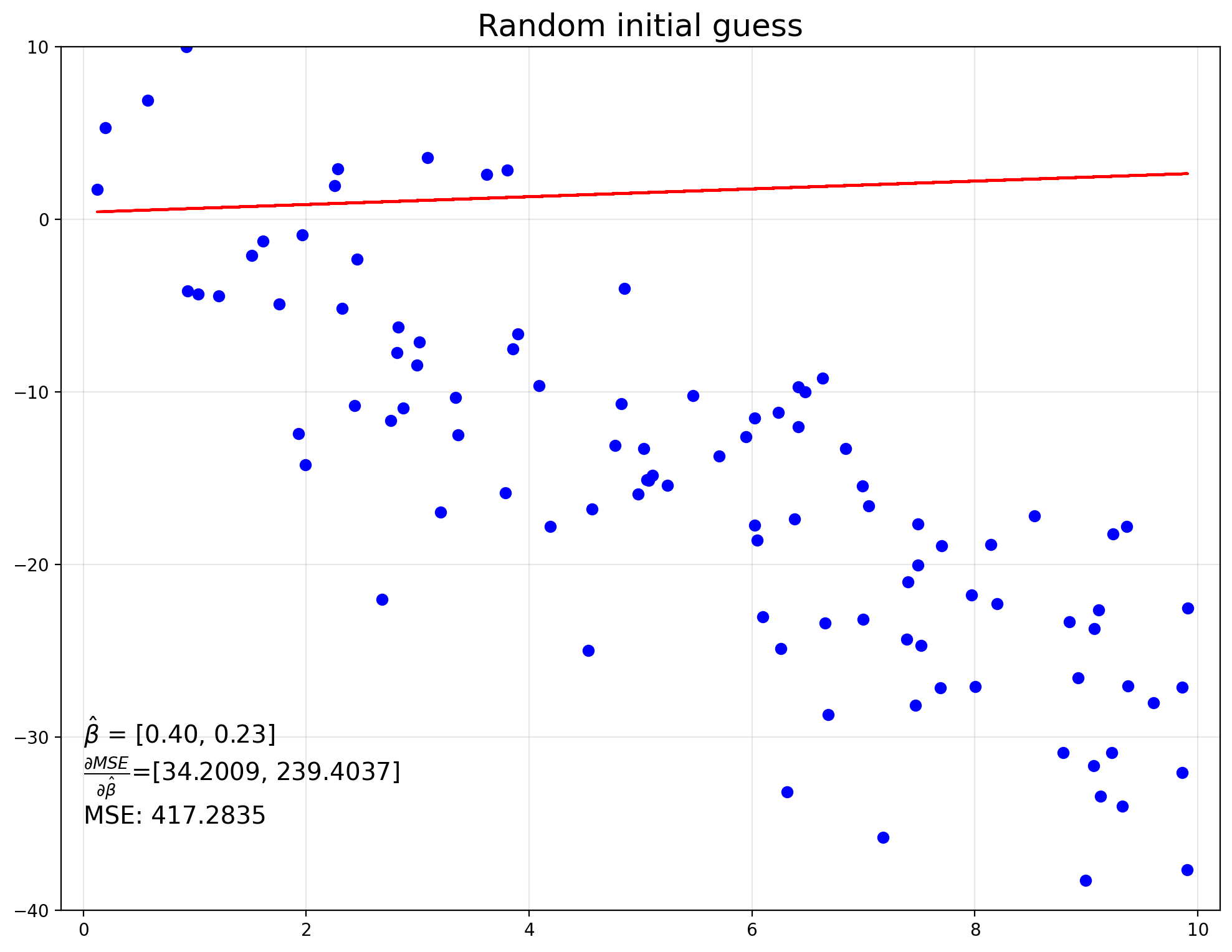
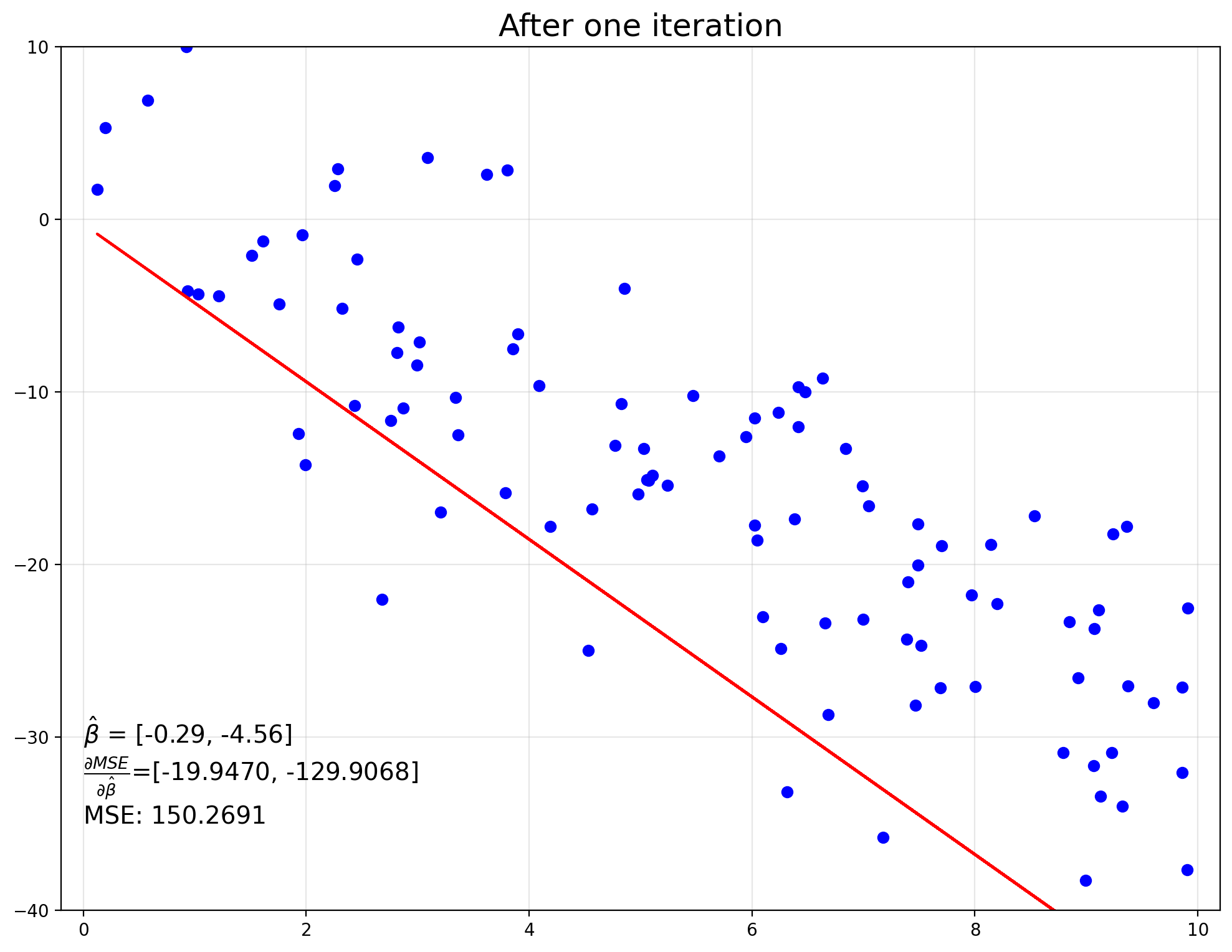
η = 0.02 # learning rate
# update β
β = β - η*gradient
# calculate new predicted Y values
y_hat = X @ β
# update gradient
gradient = -2/N * X.T @ (y - y_hat)
do_plot('After one iteration')
Here’s an animation of the first 200 steps in the iteration:
We can keep iterating until we reach some reasonable stopping point. One reasonable strategy is to stop when gradient is very small, meaning that the change between the current value of \(\beta\) and what it would be in the next iteration is very small. In other words, the estimate has converged.
n_iterations = 2500
β = np.array([[0],[0]]) # initialize to (0,0)
for i in range(n_iterations):
if i % 100 == 0: print('Iter {:>6}: {}, {}'.format(i, *β))
gradient = -2/N * X.T @ (y - X@β)
β = β - η*gradient
if abs(gradient).max()<0.0001: break
print(f'Stopped after {i} iterations')
y_hat = X @ β
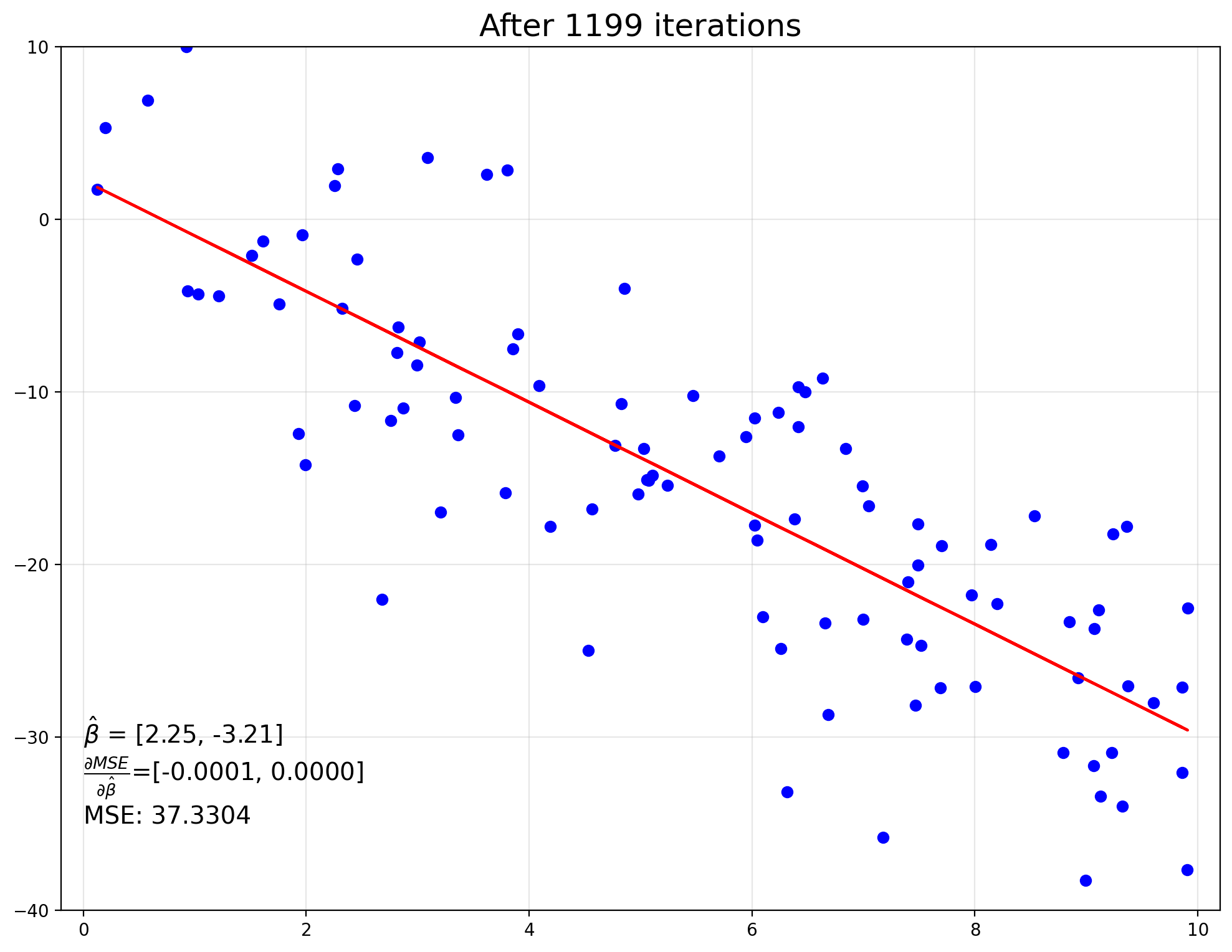
do_plot(f'After {i} iterations')
Iter 0: [0], [0]
Iter 100: [1.01677665], [-3.03221436]
Iter 200: [1.679105], [-3.1293367]
Iter 300: [1.98573382], [-3.17430007]
Iter 400: [2.12768944], [-3.19511612]
Iter 500: [2.19340864], [-3.20475304]
Iter 600: [2.22383373], [-3.2092145]
Iter 700: [2.2379192], [-3.21127997]
Iter 800: [2.24444016], [-3.21223618]
Iter 900: [2.24745907], [-3.21267887]
Iter 1000: [2.2488567], [-3.21288381]
Iter 1100: [2.24950373], [-3.21297869]
Stopped after 1199 iterations
Check your understanding
What happens when we make the learning rate \(\eta\) bigger or smaller? Experiment and see!
A similar iterative technique is used by off-the-shelf optimizers, like the one in scipy. It finds precisely the same answer we found using our iterative technique; the solution is given in the x value of the result.
from scipy.optimize import minimize
minimize(MSE, # function to minimize
x0=[0,0] # initial values for function arguments
)
message: Optimization terminated successfully.
success: True
status: 0
fun: 37.33043171791379
x: [ 2.250e+00 -3.213e+00]
nit: 6
jac: [ 0.000e+00 0.000e+00]
hess_inv: [[ 2.554e+00 -3.719e-01]
[-3.719e-01 6.738e-02]]
nfev: 21
njev: 7
Analytical solution#
We can also find an analytical solution to the problem of minimizing MSE. Setting the gradient equal to zero, we have
This implies the normal equation
which must hold for the function to be minimized. As long as \(X'X\) is invertible, this has the solution
\(X'X\) is invertible when \(K<N\), but even if it is theoretically invertible it may be computationally quite difficult if \(K\) is large.
XpX = X.T @ X
XpX
array([[ 100. , 551.1599446 ],
[ 551.1599446 , 3777.82863606]])
Notice that \(X'X\) encodes various sums calculated from the data, namely the values of \(N\), \(\sum x\) and \(\sum x^2\). It is a square matrix with dimension \(K\times K\).
# Sum of each column
X.sum(axis=0)
array([100. , 551.1599446])
# Sum of squares
(X[:,1]**2).sum()
np.float64(3777.828636059256)
We can calculate the coefficients using this equation for \(\hat{\beta}\). It should not surprise you that these are exactly what the iterative algorithm found.
from numpy.linalg import inv
beta = inv(X.T @ X) @ X.T @ y
beta
array([[ 2.25006151],
[-3.21306049]])
Regression with a single regressor#
In the simplest case, with \(K=1\), we have
so
Therefore,
Using the formula for the inverse of a \(2\times 2\) matrix, we have
where we have used the fact that
Therefore,
Similar to equation (11) above, we can also show that
Exercise
Prove equation (12). Start with the expression on the right-hand side of the equation and show that it equals the the expression on the left.
Solution
Looking at the value for second coefficient,
Solving for the first coefficient requires some additional tedious alebra, but we end up with
That is, the value of \(\hat\beta_0\) is chosen to make the the average of \(y_i\) equal to the predicted value of the average \(x_i\). In other words, it’s chosen to force the average error to be zero.
Sum of squares#
The figure below shows the residual for each observation in the data, given the optimal \(\hat\beta\) estimate.
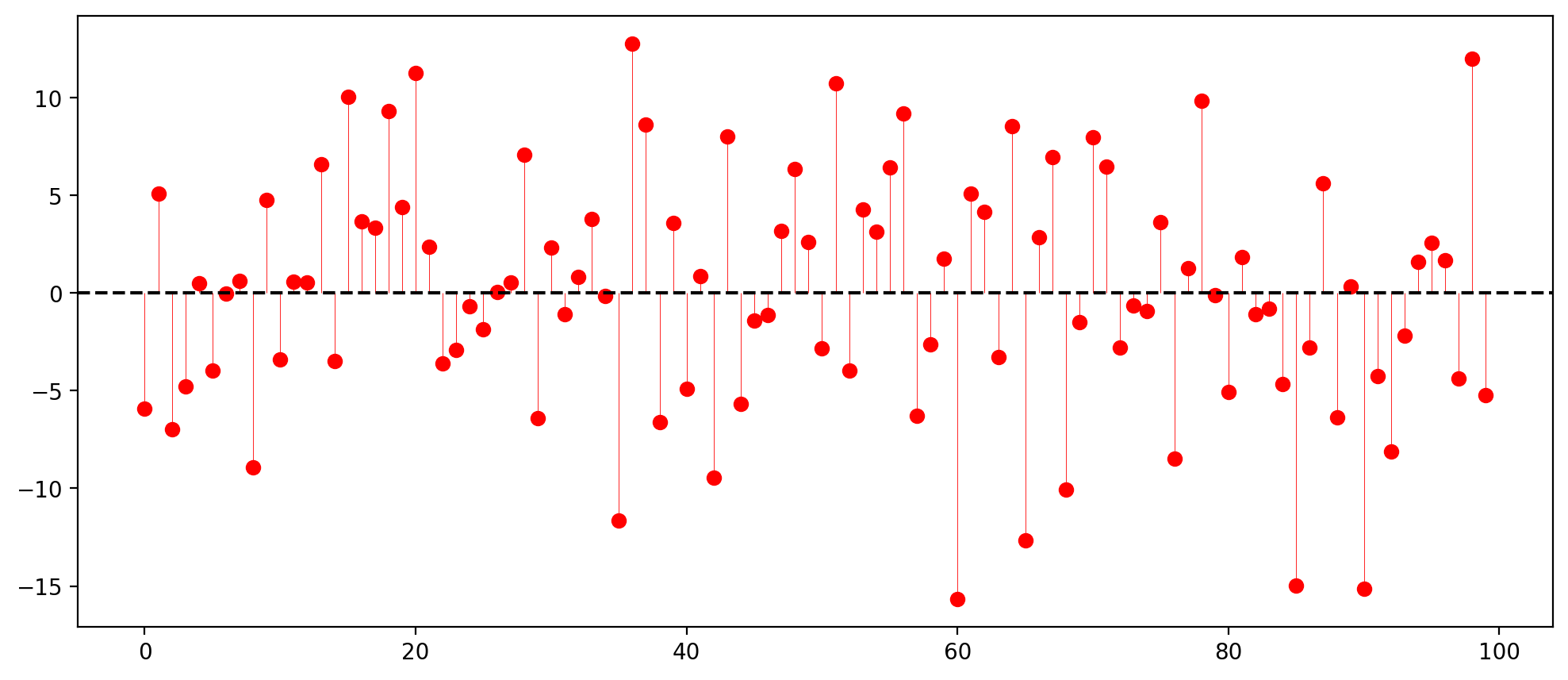
The Total Sum of Squares in the data is the sum of squared deviations from the mean,
TSS = ((y-y.mean())**2).sum()
TSS
np.float64(11373.199830388872)
The Residual Sum of Squares is the sum of squared errors,
The average of RSS provides an estimate of the variance of the noise, \(\sigma^2\):
We use the Total Sum of Squares and the Residual Sum of Squares to calculate \(R^2\), a measure of how much of the variation in the data our model can explain:
RSS = (ε_hat.T @ ε_hat).item()
print(1 - RSS/TSS)
0.6717684356677902
We are able to explain about 67% of the variance of \(Y\) with our model.